State of AI: 2023 年度人工智能报告之 Research 篇
本周四 stateof. ai 1出品了 2023 年度人工智能报告2。该报告由英国知名风投公司 Air Street Capital 的合伙人 Nathan Benaich 等联合撰写,该系列报告从 2018 年开始已经连续撰写了 6 年。除了主要作者外,还有众多研究者、机构把关,既有深度又有广度,涉及科研进展、产业界发展、政治影响、AI 安全等众多领域,涵盖了 AI 的方方面面。本文编译自该报告,并附带简单分析,期待之后有机会能够进一步深度解读,强烈推荐阅读原报告。
以下为全文目录,受限于篇幅,本报告将分为 3 篇发布,本篇为第一篇,主要关注过去一年中 AI 领域的相关突破与进展,之后两篇将在接下来的两天同步发布,敬请期待。
- State of AI 2023 报告年度总结
- 科研进展:技术突破及其能力
- 产业界发展:当前 AI 创新的商业化应用以及对应的商业化影响
- 政治影响:AI 监管,AI 产生的经济影响,AI 的地缘政治演进
- AI 安全:明确和减轻将来庞大 AI 系统可能产生的灾难性影响
- 对 2024 年的预测
01 Key Themes
- GPT-4 目前是无可匹敌的最强模型,无论是在经典基准测试还是人类评估考试中,GPT-4 n 击败了其他所有的 LLM,验证了专有架构和 RLHF 的强大能力。
- 通过使用更小的模型、更好的数据集和更长的上下文,人们正在努力克隆或超越专有模型的性能。考虑到人工生成的数据可能只能维持几年的人工智能扩展趋势,这些努力可能变得更加迫切。
- LLM 和扩散模型继续推动现实世界的突破,特别是在生命科学领域,在分子生物学和药物发现方面取得了有意义的进展。
- 算力成为新的石油,NVIDIA 创造了创纪录的收益,初创企业则以其 GPU 为竞争优势。随着美国收紧对中国的贸易限制并动员其盟友参与芯片战争,NVIDIA、英特尔和 AMD 开始大规模销售符合出口管制的芯片。
- GenAI 拯救了 VC,在科技估值下滑的背景下,专注于生成式人工智能应用(包括视频、文本和编码)的人工智能初创企业从风险投资和企业投资者那里筹集了超过 180 亿美元。
- 关于 AI 安全的辩论已经成为主流话题,引发了世界各国政府和监管机构的行动。然而,这波活动掩盖了人工智能社区内的深刻分歧和全球治理方面的实质性进展不足,因为世界各国政府追求着不同的方法。
- 在评估最先进模型的过程中面临的挑战越来越大,标准 LLM 通常很难具备鲁棒性。考虑到利害关系,仅凭「基于感觉」的方法是不够的。

02 Research
科研进展总结
- GPT-4 的发布展示了专有模型与开源替代品之间的能力差距,同时也验证了通过 RLHF 的强大能力。
- 通过使用更小的模型、更好的数据集和更长的上下文,人们正在努力克隆或超越专有模型的性能… 由 LLaMa-1/2 提供支持。
- 目前还不清楚人工生成的数据能够维持多长时间的人工智能扩展趋势(有些人估计到 2025 年,LLM 可能会耗尽数据),以及添加合成数据的影响。接下来到企业中视频和数据可能会进一步的被封闭而不开放。
- LLM 和扩散模型继续为生命科学界提供贡献,为分子生物学和药物发现带来新的突破。
- 多模态成为新的前沿领域,各种风格的 Agent 引起了极大的兴趣。
GPT-4:当之无愧的最强人工智能模型,却越来越封闭
GPT-4 is out and it crushes every other LLM, and many humans
GPT-4 是 OpenAI 最新的大型语言模型3。与仅限文本的 GPT-3 及其后续模型不同,GPT-4 是多模态的:它既在文本上进行了训练,也在图像上进行了训练;它具备了基于图像生成文本等多种能力。在发布时,它的输入大小已经超过了之前最好的 GPT-3.5,达到了 8192 个 tokens。当然,GPT-4 是使用了 RLHF 获得训练的。凭借这些进步,截至本报告发布时,GPT-4 是目前无可争议的最具综合能力的人工智能模型。
- OpenAI 对 GPT-4 进行了全面评估,不仅针对经典的自然语言处理基准进行了测试,还进行了一些旨在评估人类能力的考试(例如律师资格考试、GRE、Leetcode 等)。
- GPT-4 在各项任务上表现最佳。它解决了一些 GPT-3.5 无法解决的任务,例如统一律师资格考试,GPT-4 的得分为 90%,而 GPT-3.5 只有 10%。在大多数任务上,添加了视觉组件对性能的影响较小,但在其他任务上有很大的帮助。
- OpenAI 的报告指出,尽管 GPT-4 仍然存在虚构现象,但在对抗性真实性数据集(旨在欺骗 AI 模型)上,其事实正确性要比之前最好的 ChatGPT 模型提高了 40%。

Fueled by ChatGPT’s success, RLHF becomes MVP
在去年的安全部分(第 100 张幻灯片)中,我们强调了 RLHF 在 InstructGPT 4 中的应用,它帮助使 OpenAI 的模型对用户更加安全和有用。尽管存在一些小问题,但 ChatGPT 的成功证明了这一技术在大规模应用中的可行性。
RLHF 需要雇佣人员来评估和排名模型的输出,然后建模他们的偏好。这使得这种技术变得困难、昂贵且存在偏见5。这促使研究人员寻找替代方法。
The false promise of imitating proprietary LLMs, or how RLHF is still king
伯克利的研究人员表明,将小型 LLM 在更大、更有能力的 LLM 的输出上进行微调会产生风格上令人印象深刻但常常产生不准确文本的模型6。
- 研究人员对预训练的不同大小的 LLM 以及预训练数据量的变化进行了研究。他们表明,在固定的模型大小下,使用更多的模仿数据实际上会降低输出的质量。相反,较大的模型受益于使用模仿数据。
- 通过将模型大小作为质量的代理,作者认为应该更加关注更好的预训练,而不是在更多的模仿数据上进行微调。
- 在不久的将来,RLHF 似乎将会继续存在。在经过仔细的消融研究后,Meta 的研究人员在他们的 LLaMa-2 论文中得出结论:“我们认为 LLM 在写作能力上的卓越表现,正是由 RLHF 驱动的,体现在在某些任务上超过了人类标注者”。

Even so, researchers rush to find scalable alternatives to RLHF
在 ChatGPT 问世之后,许多实验室开始探索一个问题:我们是否能够创建与 OpenAI 的 LLM 一样具备能力和安全性,但大幅减少对人类监督的模型?
- Anthropic 提出了从 AI 反馈中进行强化学习的方法7,我们在安全性部分对此进行了介绍。
- 其他方法完全舍弃了强化学习。在 Less is More for Alignment (LIMA) 8中,Meta 提出使用一些非常精心策划的提示和回答(在他们的论文中是 1,000 个)。根据对模型输出的人类评估,LIMA 在 43%的情况下与 GPT-4 相竞争。
- 在 LLMs can self-improve9 中,Google 的研究人员展示了 LLMs 可以通过训练其自身的输出来提高性能。在类似的思路下,Self-Instruct10 是一个框架,其中模型生成自己的指令、输入和输出样本,并进行筛选以微调其参数。另一个在这个方向上的工作是 Meta 的 Self-Alignment with Instruction Backtranslation11。
- 斯坦福的研究人员使用了这最后一种方法,利用 GPT-3.5 生成指令和输出,并微调 Meta 的 LLaMa-7 B 模型12。

The GPT-4 technical report puts the nail in the coffin of SOTA LLM research…
OpenAI 在 GPT-4 技术报告中没有透露任何对 AI 研究人员有用的信息,这表明 AI 研究已经彻底工业化。Google 的 PaLM-2 技术报告遭遇了同样的命运,而 OpenAI 的分支机构 Anthropic 对其 Claude 模型也没有发布技术报告。
- 「考虑到竞争环境和 GPT-4 等大规模模型对安全性的影响,该报告不包含有关架构(包括模型大小)、硬件、训练计算、数据集构建、训练方法或类似内容的进一步细节。」OpenAI 在发布在 arXiv 上的 GPT-4 技术报告中写道。
- 当 Google 发布其最强大的 LLM——PaLM 2 时,该公司在技术报告中写道:「模型大小和架构的进一步细节被保留,不在外部发布。」
- 随着经济利益和安全关切的增加,传统上开放的公司开始对其最尖端研究采取不透明的文化态度。

LLaMA 引领开源模型风潮
…unless LLaMas reverse the trend
在 2023 年 2 月,Meta 发布了一系列名为 LLaMa 的模型。在发布时,它们因为是仅基于公开可用数据集进行训练的最强大的模型而脱颖而出。Meta 最初只向研究人员提供按需访问 LLaMa 模型权重的权限,但这些权重很快被泄露并在网络上发布。
- LLaMa-1 模型使用常规的 Transformer,对架构进行了轻微的改动。作者还对优化器和注意力的实现进行了一些修改。结果是,「当训练一个 650 亿参数的模型时,他们的代码在具有 80 GB RAM 的 2048 个 A 100 GPU 上每秒处理约 380 个标记。这意味着在包含 1.4 T 标记的数据集上训练大约需要 21 天。」
- LLaMa-1 模型在性能上超过了 GPT-3(原始版本,而不是 InstructGPT 的变体),并与 DeepMind 的 Chinchilla 和 Google 的 PaLM 相竞争。
- LLaMa-1 不允许商业使用,这引发了对 Meta 用来描述该模型发布的开源术语的严厉批评。但 LLaMa-2 缓解了大部分开源社区的担忧。

LLaMa sets off a race of open (ish) competitive Large Language Models
在 Meta 发布 LLaMa-1 之后,其他机构也加入了发布相对较大语言模型权重的行列。其中有几个引人注目,如 MosaicML 的 MPT-30 B13,TII UAE 的 Falcon-40 B14,Together 的 RedPajama15或 Eleuther 的 Pythia16。与此同时,开源社区还在对 LLaMa 的最小版本进行特定数据集的微调,并将其应用于数十个下游应用程序17。Mistral AI 的 7 B 模型18也最近成为最强的小型模型。
- 值得注意的是,RedPajama 的目标是完全复制 LLaMa-1,使其成为完全开源。Falcon 40 B 来自 LLM 竞赛的新参与者 TII UAE,并迅速成为开源项目。随后还发布了 Falcon-180 B19,但值得注意的是,它在很少的代码上进行了训练,并且没有在编码上进行测试。
- 借助 LoRa 等参数高效的微调方法(最初由 Microsoft 提出),语言模型从业者开始针对特定应用程序(当然包括聊天)对这些预训练的语言模型进行微调。一个例子是 LMSys 的 Vicuna20,它是在用户共享的 ChatGPT 会话上对 LLaMa 进行微调的。
LLaMa-2: the most generally capable and publicly accessible LLM?
在 2023 年 7 月,LLaMa-2 系列模型发布,几乎让每个人都可以进行商业使用。基础的 LLaMa-2 模型与 LLaMa-1 几乎相同,但通过指令微调和 RLHF 进一步优化,专为对话应用而设计。到 2023 年 9 月,LLaMa-2 已经下载了近 3200 万次。
- LLaMa-2 的预训练语料库有 2 万亿个标记(增加了 40%)。对于监督微调,研究人员尝试使用公开可用的数据,但最有帮助的是使用了一些(24,540 个)高质量的基于供应商的注释。对于 RLHF,他们使用了二进制比较,并将 RLHF 过程分为提示和回答,旨在对用户和其他人有所帮助,并具有安全性。
- LLaMa-2 70 B 在大多数任务上与 ChatGPT 相比具有竞争力,只是在编码方面明显落后于它。但是 CodeLLaMa 是针对编码进行微调的版本,在所有非 GPT 4 模型中都表现优秀(稍后会详细介绍)。
- 根据 Meta 的条款,只要在 LLaMa-2 发布时商业应用程序的用户数不超过 7 亿,任何人(拥有足够硬件运行模型)都可以使用 LLaMa-2 模型。
Human evaluation of LLaMa-2 helpfulness vs. other open source models
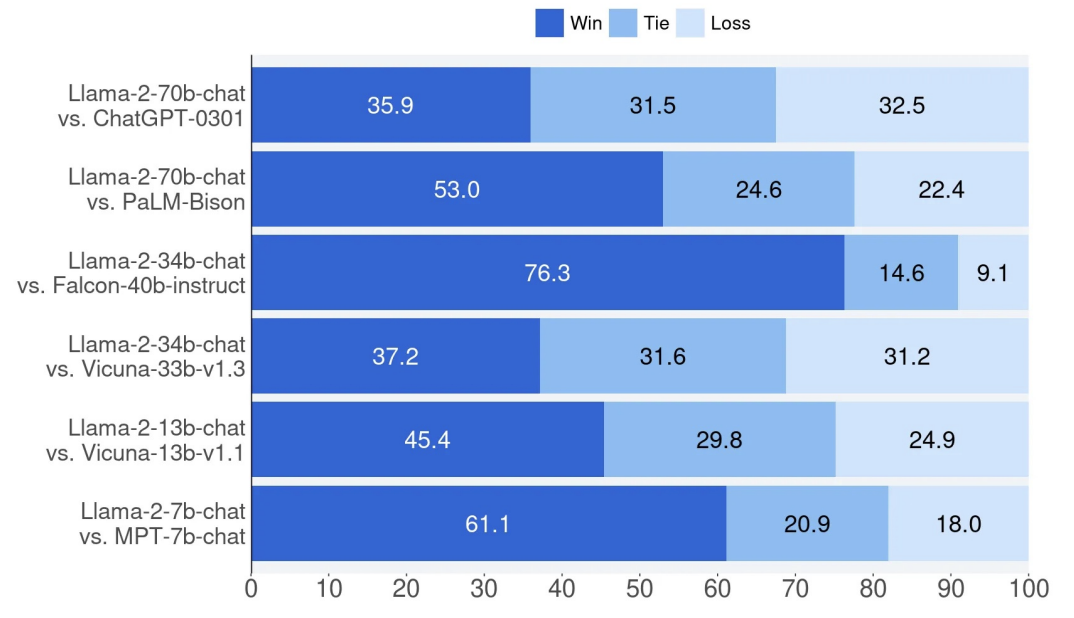
GPT and LLaMAs win the popularity contest
ChatGPT 在 X 上被提及次数最多(5430 次),其次是 GPT-4 和 LLaMa。虽然专有的闭源模型引起了最多的关注,但对于开源且允许商业使用的 LLM 的兴趣也在增加。

技术发展趋势
RLHF / Instruction-tuning emerges as the most trending topic since the end of 2022.

Are emergent capabilities of language models a mirage?
研究人员为所有类型的机器学习模型开发的扩展定律通常预测,随着参数数量和训练标记数量的增加,模型的损失会平滑地减少。相反,通常观察到,当达到某个(难以预测的)规模时,一些模型的能力实际上是出乎意料地出现的。有人对这一观察提出了质疑:新出现的能力可能只是研究人员选择的评估指标的产物21。其他人则对以下观点提出了反驳的论据22。
- 斯坦福大学的研究人员发现,涌现能力只在非线性或不连续地缩放模型的每个标记错误率的度量下出现21。
- 例如,在 BIG-Bench(一个全面的 LLM 基准测试)中,超过 92%的新出现能力出现在两个不连续的度量之一下。
- 他们在新模型上测试了自己的假设,并确认用线性或连续的替代度量代替非线性或不连续的度量会导致持续改进,而不是出现新的能力。
Emergent abilities of large language models are created by the researcher’s chosen metrics, not unpredictable changes in model behavior with scale

上下文长度
Context length is the new parameter count
AI 社区广泛验证了当模型经过正确训练时,其参数计数是其能力的一种代理。但是,这些能力有时会受到语言模型可以处理的输入大小的限制。因此,上下文长度已成为研究的一个越来越重要的主题。
- LLM 的最具吸引力的承诺之一是其少样本能力,即 LLM 能够在给定输入上回答请求,而无需进一步训练用户特定的用例。但由于计算和内存瓶颈的限制,这一能力受到上下文长度的限制。
- 已经使用了几种创新方法来增加 LLM 的上下文长度。
- 在长上下文 LLMs 中:Anthropic 的 Claude 具有 100 K 上下文长度,OpenAI 的 GPT-4 具有 32 K 上下文长度,MosaicML 的 MPT-7 B 具有 65 K+上下文长度,LMSys 的 LongChat 具有 16 K 上下文长度。
但是,上下文是否就是你所需要的一切呢?
Lost in the Middle: long contexts (mostly) don’t live up to the expectations
追求最长上下文长度的竞争建立在这样一个假设上:更长的上下文长度将导致下游任务的性能改善。来自 Samaya. Ai、UC Berkeley、Stanford 和 LMSYS. Org 的研究对这个假设提出了质疑:当输入长度很长时,即使是最好的语言模型在一些多文档问答和键值检索任务上也可能失败。27
- 研究人员发现,当任务的相关信息出现在输入的开头或结尾时,模型的性能更好,而在中间部分则会出现更大或更小的下降,具体取决于模型。他们还发现,随着输入长度的增加,模型的性能也会下降。
- 研究人员对开放模型 MPT-30 B-Instruct(8 K 长度)和 LongChat-13 B(16 K),以及封闭模型 GPT-3.5(16 K)、Claude 1.3(8 K)和 Claude 1.3-100 K 的性能进行了检查。他们发现,专有模型比开放模型更不容易出现问题28。

Keeping up with high memory demands
增加的上下文长度和大规模数据集需要进行架构创新。
- FlashAttention 通过使注意力线性化而不是与序列长度呈二次关系,实现了显著的内存节省。FlashAttention-2 通过减少非矩阵乘法操作的 FLOPS 数量、更好的并行性和更好的工作分区,进一步改进了计算注意力矩阵的过程。其结果是加速了 GPT-style 模型的训练速度 2.8 倍23。
- 减少参数中的位数可以减小 LLM 的内存占用和延迟。k-bit Inference Scaling Laws 29 的案例研究表明,在各种 LLM 模型中,4 位量化普遍是最优选择,可以最大程度地提高零样本准确性并减少所使用的位数。
- Speculative decoding30 通过 multiple model heads 而不是 forward pass 并行解码多个令牌,为某些模型加速推理速度 2-3 倍。
- SWARM Parallelism31 是一种针对连接质量差和不可靠设备的训练算法。它能够在低带宽网络和低功耗 GPU 上训练超过十亿规模的 LLM,并实现高训练吞吐量。
模型表现之于数据与模型的规模大小
Can small (with good data) rival big?
在一项仍然主要是探索性工作中,微软的研究人员表明,当使用非常专门和策划的数据集对小型语言模型(SLMs)进行训练时,它们可以与比它们大 50 倍的模型媲美。他们还发现这些模型的神经元更容易解释。
- 一个关于为什么小型模型在 narrow tasks 上通常不如大型模型的假设是,当它们在非常庞大、未经策划的数据集上进行训练时,它们会被「压垮」。
- 借助 GPT-3.5 和 GPT-4 的帮助,研究人员生成了 TinyStories32,这是一个由非常简单的短篇故事组成的合成数据集,但它捕捉到了英语语法和一般推理规则。然后,他们在 TinyStories 上训练了 SLMs,并展示了 GPT-4(作为评估工具)更喜欢由一个包含 28 M 参数的 SLM 生成的故事,而不是由 GPT-XL 1. 5 B 生成的故事。
- 在同一研究小组的另一项工作中33,研究人员选择了一个由 7 B token 组成的高质量代码和 GPT-3.5 生成的教科书和练习的合成数据集。然后,他们在这个数据集上训练了几个 SLM,包括 1.3 B 参数的 phi-1 模型,他们声称这是唯一一个在 HumanEval 上达到 50%以上的小于 10 B 参数的模型。他们随后发布了改进版的 phi-1.5 模型。

2022 Prediction: language models trained on huge amounts of data
在 2022 年的预测中,我们提到:“一种最先进的语言模型将使用比 Chinchilla 多 10 倍的数据点进行训练,证明了数据集扩展与参数扩展的关系”。尽管 OpenAI 没有确认这一点,并且我们可能不会很快知道确切情况,但在关于 GPT-4 模型大小、架构和成本的泄露信息方面,专家们似乎达成了某种共识。据报道,GPT-4 的训练数据量约为 13 万亿个标记,比 Chinchilla 多了 9.3 倍。
- Tiny Corp 的创始人 George Hotz 提出了最有可能的传闻:「Sam Altman 不会告诉你 GPT-4 拥有 220 B 参数,并且是一个包含 8 组权重的 16 路混合模型34」,而 PyTorch 的联合创始人 Soumith Chintala 也证实了这一消息35。无论是模型的总大小还是使用专家混合模型的方法都并不罕见。如果这些传闻是真实的,那么 GPT-4 的成功并没有基于根本性的创新3637。

Are we running out of human-generated data?
根据 Epoch AI 的研究38,假设当前的数据消耗和产出速率保持不变,他们预测:
- 到 2030 年至 2050 年,我们将耗尽低质量语言数据的库存
- 到 2026 年之前,我们将耗尽高质量语言数据
- 到 2030 年至 2060 年,我们将耗尽视觉数据
然而,这篇文章中提到可能挑战这些假设的显著创新包括 OpenAI 的 Whisper39 等语音识别系统,可以使所有音频数据对 LLM 可用,以及 Meta 的 Nougat 40等新的 OCR 模型。有传言称已经有大量经过转录的音频数据可供 GPT-4 使用。

Breaking the data ceiling: AI-generated content
改进生成模型的另一个视角是通过 AI 生成的内容扩大可用的训练数据池。我们还远没有得出确定性答案:合成数据变得越来越有帮助,但仍有证据表明,在某些情况下生成的数据会使模型遗忘。
- 尽管看似无穷无尽的专有和公开可用数据,但最大的模型实际上也在耗尽可供训练的数据,并且正在测试扩展定律的极限。缓解这个问题的一种方式(过去已经广泛研究过)是使用 AI 生成的数据进行训练,其数量仅受计算能力的限制。
- 谷歌的研究人员对 Imagen 文本到图像模型进行了细微调整,用于基于类别的 ImageNet,并在此基础上生成了一到十二个合成版本的 ImageNet 进行模型训练(除了原始的 ImageNet 数据)。他们表明,增加合成数据集的大小单调地提高了模型的准确性41。
- 其他研究人员表明,通过在合成文本上进行训练产生的复合误差可能导致模型崩溃42,「生成的数据最终会污染下一代模型的训练集」。前进的道路可能是进行精心控制的数据增强(像往常一样)。
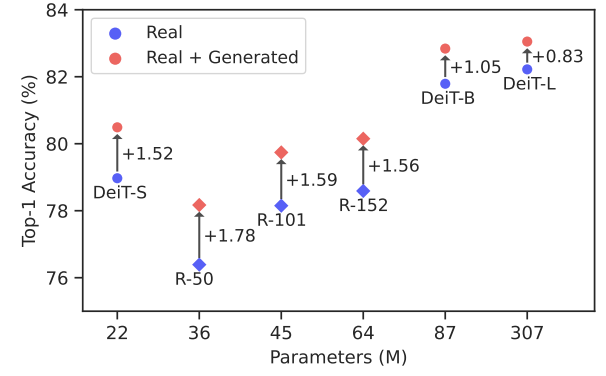
Disentangling the real and the fake, and surfacing the real behind the fake
随着文本和图像生成模型的能力不断提高,识别 AI 生成内容是否来自受版权保护的源头的长期问题变得越来越难以解决。
- 马里兰大学的研究提出了一种新的技术,用于为专有语言模型输出添加水印,即 「在文本中插入对人类来说难以察觉的隐藏模式,同时使文本在算法上可识别为合成的。」其思想是随机选择几个标记,并增加语言模型生成这些标记的概率。他们设计了一个开源算法,其中包含一个统计测试,使他们能够自信地检测水印43。
- Google DeepMind 推出了 SynthID,这是一种工具,将数字水印直接嵌入图像像素中。虽然对人眼来说难以察觉,但可以识别 Imagen 生成的图像44。
- 来自 Google、DeepMind、ETH、普林斯顿大学和加州大学伯克利分校的研究人员表明,Stable Diffusion 会记忆训练中的个别图像,并在生成时发出这些图像。作者们能够提取出 1000 多个图像,其中包括带有商标的公司标志。他们进一步表明,扩散模型比其他生成模型(如 GAN)更容易生成其训练集中的图像45。

Breaking the data ceiling: overtraining
如果我们无法获得更多原始的训练数据,为什么不在我们手头的数据上进行更多的训练呢?矛盾的研究表明,答案如常,取决于具体情况:通常情况下,进行一到两个 epochs 的训练是最佳选择;在某些情况下,再进行几个 epochs 的训练可能会有所帮助;但是,过多的 epochs 通常等于过拟合。
- 在大规模深度学习时代之前(比如 GPT-2 之后),大多数模型都会对给定的数据集进行多个 epochs 的训练。但随着模型的规模越来越大,进行多个时期的训练几乎总会导致过拟合,这促使大多数从业者选择在可用数据上进行单个 epoch 的训练(这在理论上是最优的做法)4647。
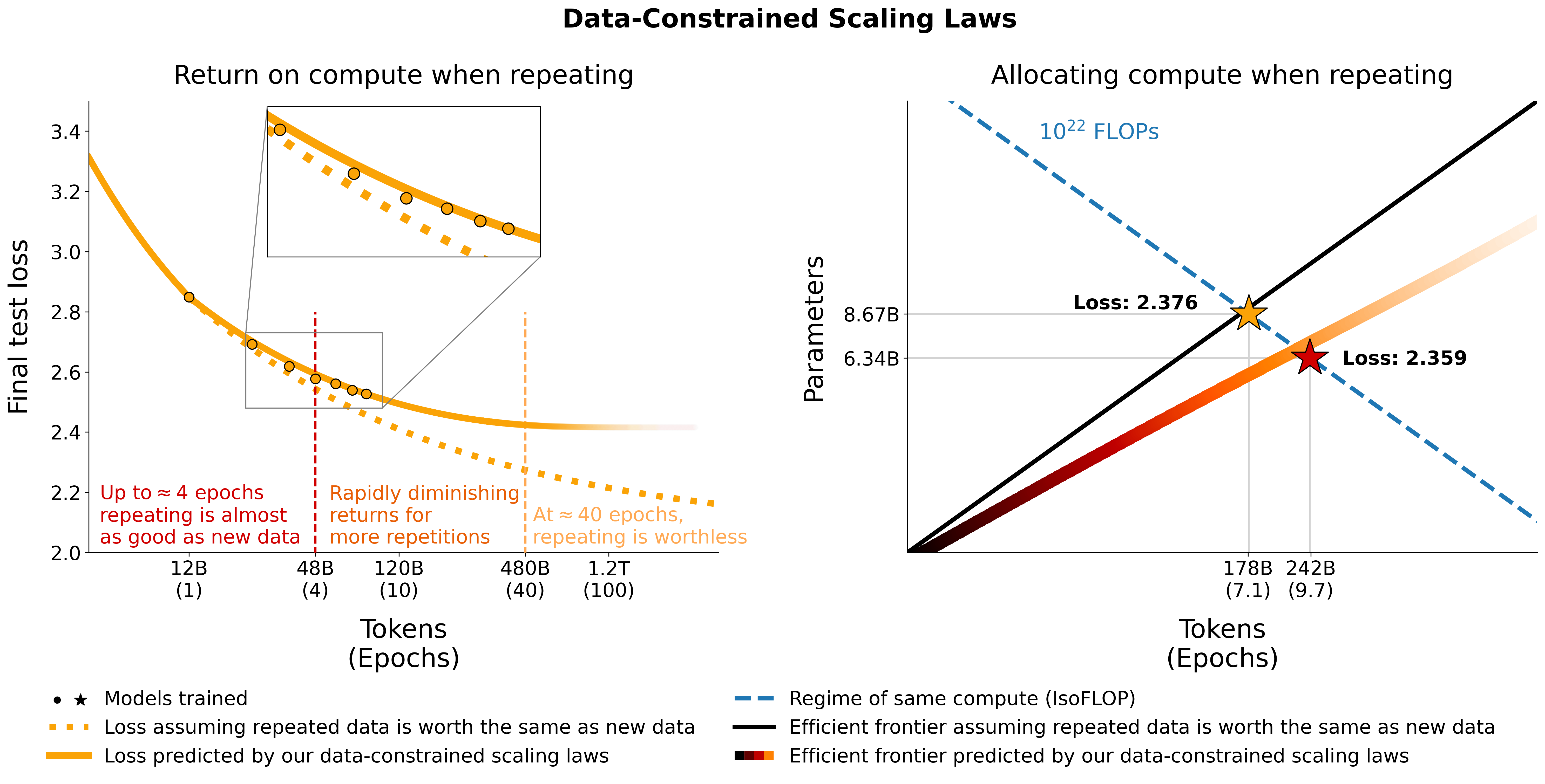
如何更好地评估模型的表现
Vibe check: evaluating general-purpose LLMs leaderboards and “vibes”
随着开放和封闭的 LLMs 的增多,用户面临着大量在更多或更少相同数据上训练的非差异化 LLMs。根据具有挑战性的基准测试,斯坦福大学的 HELM 排行榜和 Hugging Face 的 LLM 基准测试似乎是比较模型能力的当前标准。但是在基准测试或其组合之外,对于如此灵活的模型,用户似乎更偏向于更主观的「氛围」。
- HELM 基准测试的座右铭是评估尽可能多的因素,将具体的权衡选择留给用户。它在 42 个场景(基准测试)上使用 59 个指标评估模型。指标的类别包括准确性、稳健性、公平性、偏见等等48。
- 与包含开放和封闭 LLMs 的 HELM 不同,Hugging Face 的基准测试仅比较开放 LLMs,但它似乎比 HELM 更经常受到评估(评估最大模型也更加昂贵)49。
- 尽管基准测试相对动态,根据万能的机器学习真相源头 Twitter/X 的说法,用户倾向于忽视排行榜,在应用 LLMs 到特定用例时只信任他们的「氛围」50。

代码模型
State of LMs for code
毫不奇怪,GPT-4 在编码能力方面是当之无愧的领先者,其 Code Interpreter 或者现在的 Advanced Data Analysis 令用户惊叹不已。像 WizardLM 的 WizardCoder-34 B 和 Unnatural CodeLLaMa 这样的开源替代品在编码基准测试中与 ChatGPT 不相上下,但它们在实际生产中的表现仍待定。
- Unnatural CodeLLaMa 和 WizardCoder 都不仅在大型预训练编码数据集上进行了训练,还使用了适用于代码数据的额外的语言模型生成的指导微调技术。Meta 使用了他们的 Unnatural Instructions51 ,而 WizardLM 使用了他们的 EvolInstruct。值得注意的是,CodeLLaMa 是以一种使模型能够进行插值(而不仅仅是从过去的文本中进行完成)的方式进行训练的,除了 Unnatural CodeLLaMa 外,所有的 CodeLLaMa 模型都已发布。
- 较小的面向代码的语言模型(包括 replit-code-v 1-3 b 和 StarCoder 3 B)在代码完成任务上既具有低延迟又具有良好的性能。它们支持在边缘进行推理(例如在 Apple Silicon 上的 ggml),促进了对 GitHub Copilot 的注重隐私的替代方案的发展。

AlphaZero is DeepMind’s gift that keeps on giving, now for low-level code optimization
DeepMind 发布了 AlphaDev52,这是一个基于 AlphaZero 的深度强化学习代理程序,用于优化将高级代码(例如 C++或 Python)转化为机器可读的二进制代码时使用的低级汇编代码。通过对现有算法进行简单的删除和修改,AlphaDev 找到了一种方法,可以将小序列的排序速度提高高达 70%。
- AlphaZero 曾被用于在国际象棋、围棋和将棋等游戏中达到超人水平,甚至用于改进芯片设计53。
- AlphaDev 将代码优化重新定义为强化学习问题:
- 在时间 t,状态是生成的算法、内存和寄存器的表示
- Agent 程序然后编写新指令或删除旧指令
- 其奖励取决于正确性和延迟
- 对于大于 250 K 的序列,发现的 sort 3、sort 4 和 sort 5 算法改进了约 1.7%。这些算法已在广泛使用的 LLVM 库中开源52。
- 有趣的是,通过仔细的提示,一位研究人员成功让 GPT-4 提出了与 AlphaDev 的 sort 3 非常相似(非常简单)的优化方法54。

Prompt Engineering
Where are we prompting? Take a deep breath…it’s getting sophisticated
Prompt 的质量极大地影响任务的性能。思维链提示(CoT)要求语言模型额外输出中间的推理步骤,从而提高性能。思维树提示(ToT)通过多次采样并将“思考”表示为树结构中的节点进一步改进。
- ToT55 的树结构可以用多种搜索算法来探索。为了利用这种搜索过程,语言模型还需要为节点分配一个值,例如将其分类为确定、可能或不可能之一。思维图(GoT)56通过合并相似的节点将这个推理树转化为图形。
- 事实证明,语言模型本身也是出色的提示工程师。自动思维链(Auto-CoT)57在 10 个推理任务上与思维链(CoT)的性能相匹配甚至超过。自动提示工程师(APE)58 在 24 个任务中有 19 个任务表现相同。APE 设计的提示还可以引导模型朝向真实性和/或信息性的方向发展。通过提示进行优化(OPRO)的研究59表明,在 GSM 8 K 和 Big-Bench Hard 等任务上,经过优化的提示的性能明显优于人类设计的提示,有时甚至超过 50%。

Prompt
engineeringtrial and error
下游任务高度依赖于底层 LLM 的性能。然而,尽管 GPT 模型在不断更新,但 OpenAI 并没有公布对同一版本的更改。据用户反馈,相同的 LLM 版本在不同时间表现出截然不同的性能。每个人都不得不持续监控性能,并仔细更新精心策划的提示。
- How is ChatGPT’s Behaviour Changing over Time? 60 报告显示,GPT 3.5 和 GPT 4 在 2023 年 3 月和 2023 年 6 月的版本在数学问题(下图)、敏感问题、意见调查、知识问题、生成代码、美国医疗执照考试和视觉推理等任务上性能有所差异。

Agent 生态
Welcome, Agent Smith: LLMs are learning to use software tools
目前,LLMs 对经济产生最直接影响的方式是使它们能够调用各种外部工具。最常见的工具是网络浏览器,允许模型保持最新状态,但从业者们正在通过 API 调用对语言模型进行微调,以使其能够使用几乎任何可能的工具。
- 一个使用工具的 LLM 的例子是 Meta 和 Universitat Pompeu Fabra 的 Toolformer61,研究人员以自我监督的方式训练基于 GPT-J 的模型,「决定何时调用哪些 API、传递什么参数以及如何将结果最好地融入未来的标记预测中」。值得注意的是,在训练过程中,Toolformer 会对 API 调用进行采样,并仅保留那些能够降低训练损失的调用。
- 有些模型的焦点更加狭窄,比如 Google 的 Mind’s eye,模型会运行物理模拟来回答物理推理问题,而其他模型则将这种方法扩展到了数万种可能的外部工具上。
- 能够使用外部工具的 LLMs 通常被称为 Agent。除了学术研究之外,我们还看到了工业界和开源社区开发的多个工具,其中最著名的是 ChatGPT 插件、Auto-GPT62 和 BabyAGI63。

Open-ended learning with LLMs
LLMs 能够生成和执行代码,因此它们可以成为开放式世界中强大的规划代理。其中最好的例子是 Voyager64,这是一个基于 GPT-4 的 Agent,能够在 Minecraft 中进行推理、探索和技能获取。
- 通过迭代地提示 GPT-4(LLMs 在一次性代码生成方面仍然存在困难),Voyager 生成可执行的代码来完成任务。需要注意的是,很可能 GPT-4 已经看过大量与 Minecraft 相关的数据,因此这种方法可能不适用于其他游戏。
- 代理通过使用 Minecraft API 通过明确的 JavaScript 代码与环境进行交互。如果生成的代码成功完成任务,它将被存储为新的「技能」,否则 GPT-4 将根据错误再次进行提示。GPT-4 根据 Voyager 的状态生成任务课程,以鼓励它逐渐解决更难的任务。
- 在没有任何训练的情况下,Voyager 获得了比之前的 SOTA 更多 3.3 倍的独特物品,行程距离更长 2.3 倍,并且以最多 15.3 倍的速度解锁了关键技术树里程碑。

Reasoning with language model is planning with a world model
传统上,推理被视为在可能的结果空间中搜索并选择最佳结果。由于 LLMs 包含了关于世界的大量信息,它们提供了生成这个空间(通常称为世界模型)的机会,规划算法可以在其中进行探索。基于规划的推理(RAP)使用蒙特卡洛树搜索来高效地找到高回报的推理路径65。
- 世界模型可以生成一个动作,并预测通过采取该动作达到的下一个状态。这产生了一个推理轨迹,使得 LM 比 CoT 方法更连贯,后者只能预测下一个动作,而不能预测下一个世界状态。奖励也是从 LM 中获得的,并用于维护用于 MCTS 规划的状态-动作值函数。
- 尽管成本更高,但 RAP 在计划生成、数学推理和逻辑推理方面表现优于 CoT 推理方法。在 Blocksworld 环境中,LLaMA-33 B 上的 RAP 甚至在 GPT-4 上胜过 CoT。

GPT-4 out-performs RL algorithms by studying papers and reasoning
另一个基于 GPT-4 的纯文本代理是 SPRING66。它在没有训练的情况下在开放式世界游戏中胜过了最先进的强化学习基准。它通过 LLM 阅读游戏的原始学术论文,并通过推理来进行游戏。
- 尽管强化学习在像 Minecraft 和 Crafter 这样的基于游戏的问题中一直是首选,但它受到高样本复杂性和整合先前知识的困难的限制。相比之下,LLM 可以处理论文的 LaTeX 源代码,并通过问答框架(以问题为节点、以依赖关系为边的有向无环图)进行推理,以采取环境行动。


Vision-Language Models
Vision-language models: GPT-4 wins (but API access is still limited)
在一个名为 VisIT-Bench 67 的新的视觉指令基准测试中,包含 592 个带有人工编写的标题的查询,视觉语言模型与人工验证的 GPT 4 进行了测试,大多数模型都没有达到预期。
- 根据人工评估员的评价,最好的模型是 LLaMa-Adapter-v 2,尽管它在 VisIT-Bench 上只有 27.4%的情况下击败了 GPT 4 验证的参考标题。
- 今年早些时候,Salesforce 发布了一款引人注目的多模态模型 BLIP-2。它在 VQAv 2 上的性能优于闭源的 Flamingo,而可训练参数仅为后者的 1/54。BLIP-2 使用了现成的冻结的 LLM,现成的冻结的预训练图像编码器,并且只训练了一个小型 Transformer。
- 然而,它的改进版本 InstructBLIP 在 VisIT-Bench 上对 GPT 4 参考标题的胜率仅为 12.3%。
Leveraging LLMs and world knowledge for compositional visual reasoning
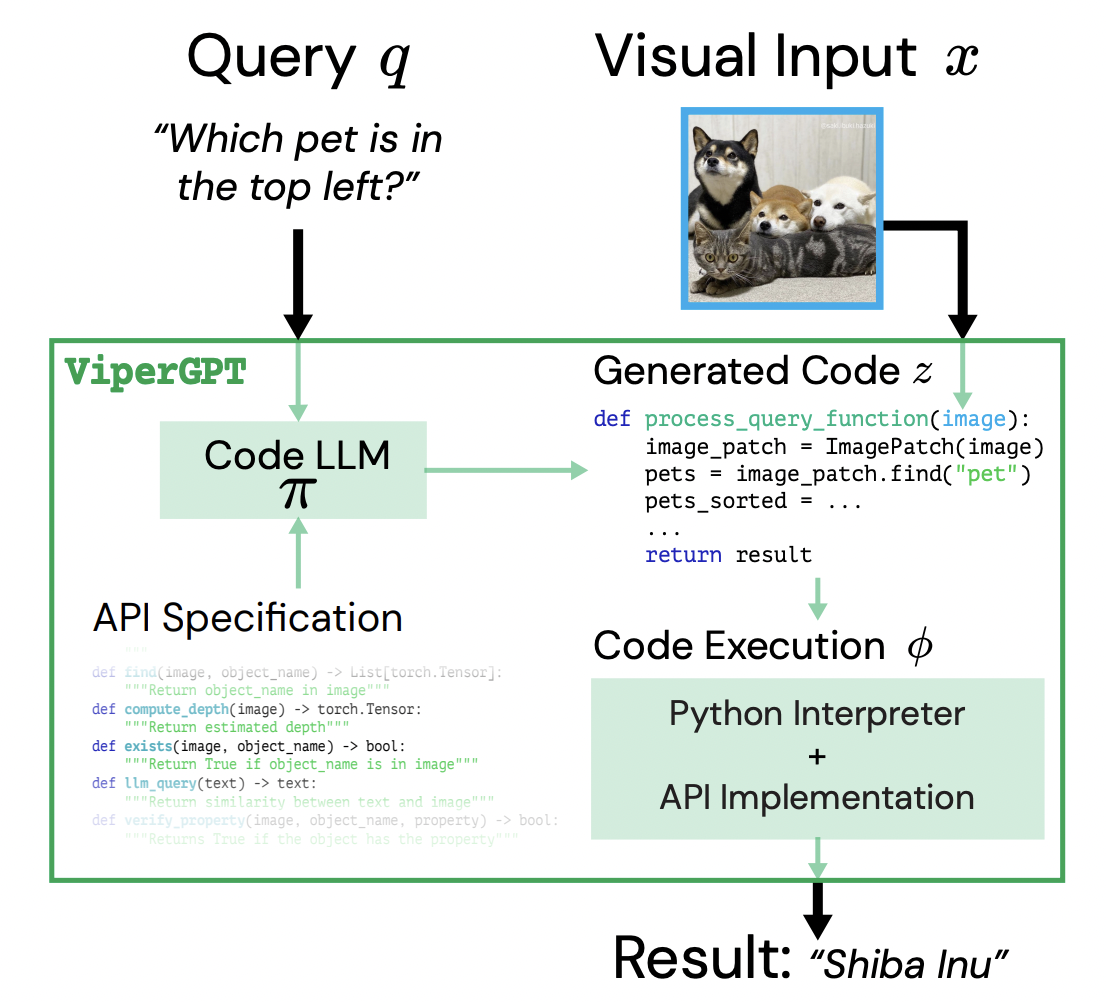
两种方法 VisProg68 和 ViperGPT69 展示了如何通过给定一个关于图像的自然语言查询,LLM 可以将其分解为一系列可解释的步骤,这些步骤调用预定义的 API 函数来执行视觉任务。
- 视觉编程方法旨在通过组合式的多步推理而不是端到端的多任务训练来构建通用的视觉系统。这两种方法都使用完全现成的组件。
- 用于视觉基元的 API 调用现有的 SOTA 模型(例如语义分割、对象检测、深度估计)。
- ViperGPT 使用 Codex 直接生成基于 API 的 Python 程序,可以使用 Python 解释器执行这些程序。VisProg 通过使用伪代码指令的示例提示 GPT-3,并将其解释为“视觉程序”,依赖于 LLM 的上下文学习。
- 在训练时,LLMs 从互联网规模的数据中获得的世界知识有助于视觉推理任务(例如基于检测到的品牌在图像中查询非酒精饮料)。这两种方法在各种复杂的视觉任务中展现了最先进的结果70。
具身智能
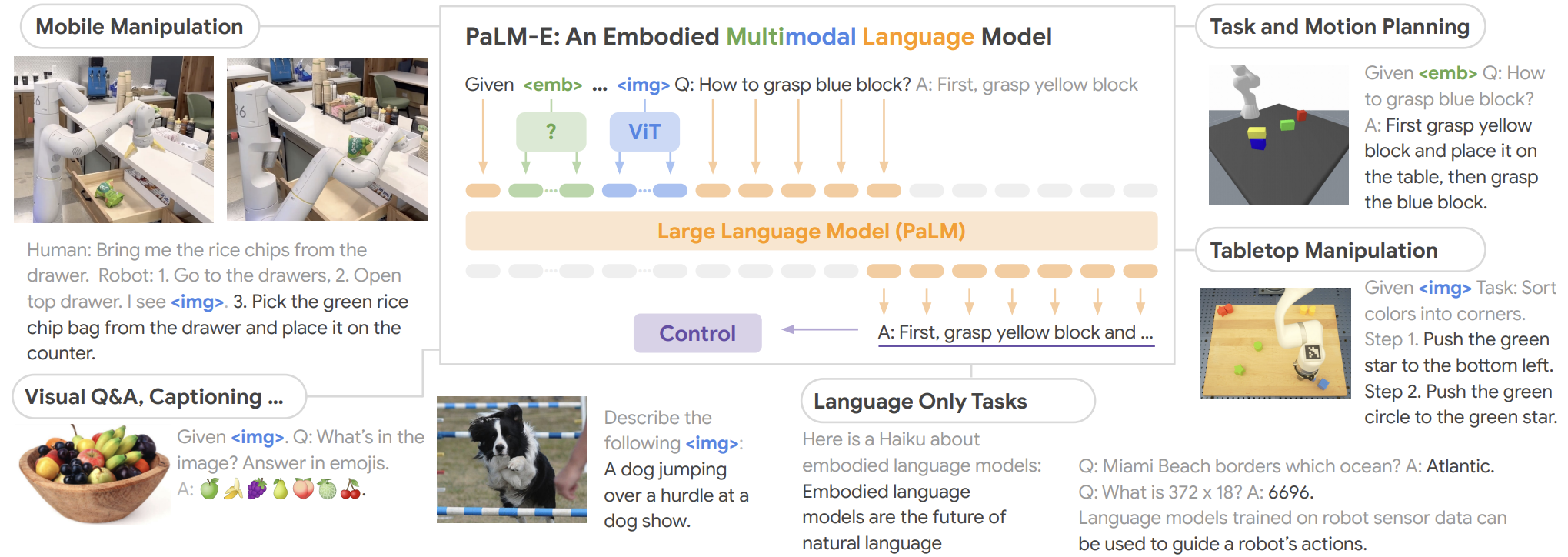
PaLM-E: a foundation model for robotics71
PaLM-E 是一个拥有 562 B 参数的通用型机器学习模型,它通过对视觉、语言和机器人数据的训练而得到。它可以实时控制机械臂,并在视觉问答基准测试中取得了最新的最优结果。由于其具有具身智能的优势,PaLM-E 在纯语言任务(尤其是涉及地理空间推理的任务)上表现更好,相比仅处理文本的语言模型。
- 该模型结合了 PaLM-540 B 和 ViT-22 B,并允许输入文本、图像和机器人状态。这些输入与单词 token embeddings 被编码到相同的空间,然后输入到语言模型中进行下一个标记的预测。
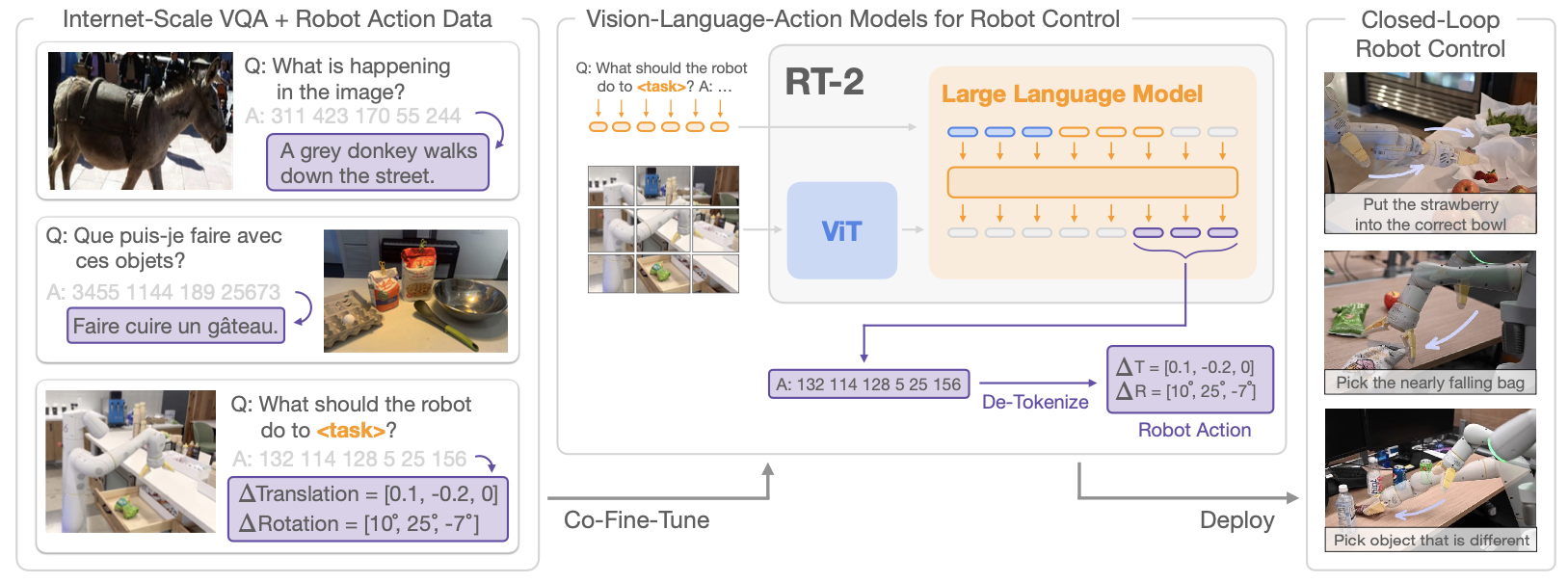
From vision-language models to low-level robot control: RT-272
视觉语言模型可以通过微调一直优化到低级策略,展示出在操纵物体方面的令人印象深刻的性能。它们还保留了对网络规模数据进行推理的能力。
- RT-2 将动作表示为 tokens,并训练视觉语言动作模型。与仅在机器人数据上进行 naive finetuing 不同,RT-2 在机器人动作上同时对 PaLI-X 和 PaLM-E 进行共同微调(机器人末端执行器的 6 自由度位置和旋转位移)。
- 互联网规模的训练使得模型能够推广到新颖的对象,解释不在机器人训练数据中的命令,并进行语义推理(找出作为 improvised hammer 的物体)。
- 为了实现高效的实时推理,RT-2 模型部署在一个多 TPU 云服务中。最大的 RT-2 模型(55 B 参数)可以以 1-3 Hz 的频率运行。
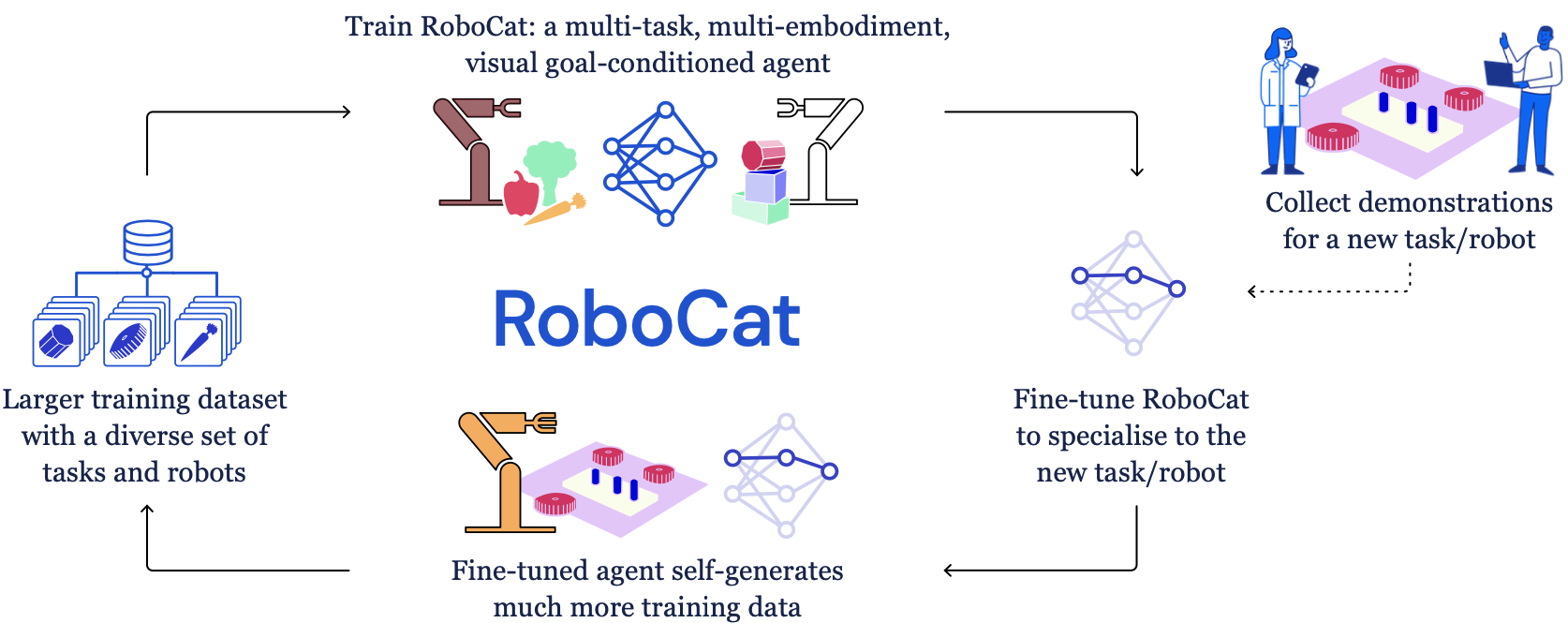
From vision-language models to low-level robot control: RoboCat73
RoboCat 是一个用于机器人操作的基础代理程序,可以在零样本或少样本(100-1000 个示例)情况下推广到新任务和新机器人。在各种平台上展现出令人印象深刻的实时性能。
- 它是基于 DeepMind 的多模态、多任务和多体现 Gato 构建的。它使用了一个经过冻结的 VQ-GAN 标记器,该标记器在多种视觉和控制数据集上进行了训练。虽然 Gato 只预测动作,但 RoboCat 还会额外预测未来的 VQ-GAN 标记。
- 在策略学习方面,论文只提到了行为克隆。RoboCat 通过少数示范(通过远程操作)进行微调,并重新部署以生成给定任务的新数据,在后续训练迭代中不断自我改进。
- RoboCat 可以以令人瞩目的速度(20 Hz)在 253 个任务的 134 个真实对象上操作 36 个具有不同动作规范的真实机器人。
LLM 与自动驾驶
Leveraging LLMs for autonomous driving
LINGO-174是 Wayve 的视觉语言行动模型,它提供驾驶建议,例如有关驾驶行为或驾驶场景的信息。它还可以以对话方式回答问题。在可解释性方面,LINGO-1 可以成为颠覆性的一步,改善端到端驾驶模型的解释能力,并提升推理和规划能力。

An autonomous system that races drones faster than human world champions
这是机器人在竞技运动(一人称视角无人机竞速)中首次获胜。Swift 75是一个自主系统,可以使用仅依靠机载传感器和计算能力就能使四旋翼无人机达到人类世界冠军的水平。它在与 3 名冠军进行的几场比赛中获胜,并创下了最快记录时间76。
- Swift 使用了基于学习和传统技术的组合。它将 VIO 估计器与门探测器相结合,通过卡尔曼滤波器估计无人机的全局位置和方向,从而获得准确的机器人状态估计。
- Swift 的策略使用基于模型的无模型深度强化学习在模拟环境中进行训练,奖励结合了向下一个门的前进和保持其在视野范围内(这增加了姿态估计的准确性)。当考虑感知中的不确定性时,竞赛策略在模拟环境和真实环境之间能够良好地迁移。

The emergence of maps in the memories of blind navigation agents
地图构建是 AI 代理学习导航过程中的一种新兴现象。它解释了为什么我们可以将图像输入神经网络中,而不需要显式的地图,并且可以预测导航策略。
- The Emergence of Maps in the Memories of Blind Navigation Agents77 研究表明,仅仅给予 Agent 关于自我运动的知识(代理物体在移动过程中的位置和方向的变化)和目标位置就足以成功导航到目标位置。需要注意的是,该代理没有任何视觉信息作为输入,然而与「有视觉」的代理相比,它的成功率非常相似,只是效率略有不同。
- 该模型没有任何关于地图构建的归纳偏向,并且使用基于策略的强化学习进行训练。唯一解释这种能力的机制是 LSTM 的记忆。
- 可以仅通过该代理的隐藏状态来重构度量地图并检测碰撞。

策略游戏
CICERO masters natural language to beat humans at Diplomacy78
Meta 训练了一个 AI 代理程序来玩一款名为 Diplomacy 的流行多人策略游戏,该游戏涉及通过自然语言与其他玩家在多个回合中进行规划和协商。CICERO 的得分是在线人类玩家平均得分的两倍,并跻身于玩过一局以上的玩家中排名前 10%。
- 在战略规划和语言建模方面的快速并行进展为在这两个领域的交叉点上带来了潜在的巨大进步,可以应用于人工智能与人类的合作。Meta 将 Diplomacy 游戏作为这一进展的基准。
- CICERO 使用玩家之间的对话历史以及棋盘状态和历史来开始预测每个人将要采取的行动。然后,它使用规划逐步完善这些预测,并根据策略决定自己打算采取的行动。CICERO 然后生成和过滤与其他玩家进行交流的候选消息。
- 它使用的可控对话模型是基于一个类似于 BART 的 2.7 B 参数模型,在超过 40,000 场 Diplomacy 在线游戏上进行了微调。CICERO 使用了一种基于 piKL 的新的迭代规划算法,在与其他玩家对话后提高了对其行动预测的准确性。


视频生成
The text-to-video generation race continues
与去年类似(第 33 页)79,竞赛主要集中在 video diffusion 和 masked transformer 模型之间(尽管从算法上两者非常相似)。去年的 Make-a-video 和 Imagen 基于扩散模型,而 Phenaki 则基于双向 masked transformer 模型。
- VideoLDM 80是一个 latent diffusion model,能够生成高分辨率的视频(最高可达 1280 x 2048!)。它们基于预训练的图像扩散模型,通过时间上的微调和时间对齐层将其转化为视频生成器
- MAGVIT81 是一种 masked generative video transformer。类似于 Phenaki,它使用 3 D 标记器来提取时空标记。它引入了一种新颖的掩蔽方法。它在视频生成基准测试中具有最佳的 FVD 指标,并且比视频扩散模型快 250 倍。
Instruction based editing assistants for text-image generation
去年出现了许多文本-图像生成模型,如 DALLE-2、Imagen、Parti、Midjourney、Stability 等。但是要控制生成过程需要对提示和自定义语法进行大量实验。今年出现了新的方法,使得图像生成和编辑具备了类似联合驾驶员(co-pilot)的能力。
- InstructPix 2 Pix 82 利用预训练的 GPT 3 和 StableDiffusion 生成了一个大型数据集,包含{输入图像,文本指令,生成图像} 三元组,用于训练一个受监督的条件扩散模型。然后,编辑过程以前馈方式进行,无需对每个图像进行微调或反转,可以在几秒钟内进行修改。
- 像 Imagen Editor 83 这样的 Masked inpainting 方法需要向模型提供一个覆盖层或 mask,用于指示要修改的区域,同时提供文本指令。
- 在这些方法的基础上,像 Genmo AI 84 的 Chat 这样的初创公司提供了一个类似联合驾驶员的界面,用于通过文本引导进行图像生成和语义编辑。


3D 渲染
Welcome 3D Gaussian Splatting85
基于 3 D 高斯点云的新 NeRF 竞争者展示了令人印象深刻的质量,并实现了实时渲染。
- 3D 高斯点云渲染不是学习神经网络的参数,而是学习了数百万个高斯分布(每个 3D 点一个),通过计算每个高斯对最终图像中的每个像素的贡献来进行光栅化。
- 需要更多表现力的区域使用更多的高斯点云,同时避免了在空白区域进行不必要的计算,这就是为什么与 NeRF 类似,场景看起来如此精细详细的原因。
- 现在可以以高质量实时(≥ 100 fps)在 1080 p 分辨率下渲染新视角。
- 请注意,Zip-NeRF86 在相同数据集(多尺度 360)上的训练时间为 53 分钟,PSNR 为 28.54。

- Left: MipNeRF 36087, 0.06 fps, Train: 48 h, PSNR: 27.69
- Right: 3 D Gaussian Splatting, 134 fps, Train: 41 min, PSNR: 27.21
NeRFs meet GenAI
基于 NeRF 的生成模型是大规模创建 3D 物料的一个有前途的方向。NeRF 不仅在速度和质量上有所提升(参见 HyperDiffusion88、MobileNeRF89、Neurolangelo90 和 DynIBaR91),还使得 GenAI 能够对 3 D 几何进行建模。
- DreamFusion 92 和 Score Jacobian Chaining93 是首批使用预训练的 2D 文本-图像扩散模型进行文本-3D 合成的方法。早期的尝试展示了单个对象的卡通风格的 3D 模型。
- RealFusion94 通过对特定图像进行扩散先验微调,增加了该图像的可能性。
- SKED95 仅修改通过几个引导草图提供的 NeRF 的选定区域。它们保持了基本 NeRF 的质量,并确保编辑区域符合文本提示的语义
- Instruct-Nerf 2 Nerf96 对整个 NeRF 场景进行编辑,而不是只编辑区域或从头开始生成。他们在每个输入图像上应用潜在的扩散模型,并迭代地更新 NeRF 场景,确保它保持一致性。
图像生成与分割
Zero-shot metric depth is here
最近,Zero-shot metric depth models 被用作更好的图像生成的条件。这仅需要相对深度预测,而其他下游应用(如机器人学)需要度量深度,然而迄今为止,度量深度在不同数据集之间的泛化效果不佳。
- ZeroDepth: Towards Zero-Shot Scale-Aware Monocular Depth Estimation97 可以预测来自不同领域和不同相机参数的图像的度量深度。它联合编码图像特征和相机参数,使网络能够推理对象的大小并在变分框架中进行训练。深度网络最终学习到可以在数据集之间转移的“尺度先验”。
- ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth98 是一个相对深度模型,附加了在度量深度上进行微调的模块。这是第一个在多个数据集上进行训练而不显著降低性能,并且能够在室内和室外领域中泛化的模型。

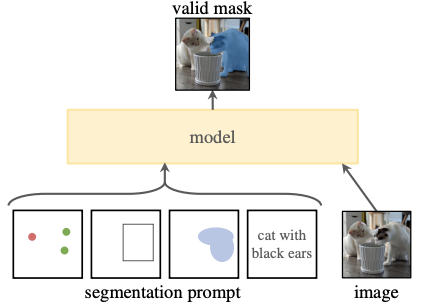
Segment Anything: a promptable segmentation model with zero-shot generalisation99
Meta 推出了一个名为 Segment Anything 的大规模项目,其中包括在一个 11 M 图像数据集(SA-1 B)上释放了 1 B 个分割掩码,并提供了一个带有 Apache 2.0 商业使用许可的分割模型(SAM)。Meta 在 23 个不同领域的图像数据集上对 SAM 进行了测试,在 70%以上的情况下超过了现有的最先进技术。
- 受到预训练在大规模数据集上并通过 prompt 展现 zero-shot 能力的大型语言模型的启发,Meta 的研究人员着手构建一个模型,可以实现通用的可提示分割:给定任何提示,模型应该能够识别和分割任何图像中的任何对象。
- 该模型由两个组件组成:
- 一个重量级编码器(ViT)用于计算一次性图像嵌入
- 一个轻量级交互模块(可以在浏览器上在 CPU 上运行),包括一个将用户提示进行嵌入的提示编码器和一个预测分割掩码的掩码解码器。
- 使用 model-in-the-loop 的数据引擎生成训练数据,最终的 SA-1 B 完全自动地通过应用 SAM 生成。
- 通过提示工程,SAM 可以应用于其他任务,包括边缘检测、对象提议生成和实例分割,并初步展示了结合 SAM + CLIP 进行文本提示的结果。
DINOv 2: the new default computer vision backbone
DINOv 2100 是 Meta 推出的一种自监督视觉 Transformer 模型,可以生成通用的视觉特征,可用于各种图像级别(例如分类)和像素级别(例如分割)的任务,无需微调,并且在与最先进的开源弱监督替代方法竞争时表现出色。
- 这是首个弥合自监督和弱监督方法差距的工作。DINOv 2 的特征被证明包含有关对象部分以及图像的语义和低级理解的信息。
- 作者通过额外的正则化方法使自监督学习模型的训练更稳定,并降低了内存需求,从而能够在更多数据上更长时间地训练更大的模型。他们还通过蒸馏提供了模型的压缩版本。
- 尽管可以使用任何图像进行训练,但关键组成部分是策划数据集并在概念之间自动平衡数据(保留了 12 亿源图像中的 1.42 亿个)。
- 使用线性分类器可以利用 DINOv 2 的特征在许多视觉任务上获得强大的结果。

天气预报与模拟
More accurate weather predictions, in the now (casts) and the longer ranges
目前,短期降水预测(即时预报)存在模糊、易消散和速度较慢的问题。使用准确的数值天气预报方法进行中期全球天气预报在计算上代价高昂。针对这两个问题,学习方法和融合相关先验知识的物理信息模型能够提供专业气象学家所青睐的性能改进。新的基准数据集,如谷歌的 WeatherBench 2101,有助于数据驱动的天气模型开发。
- Pangu-Weather102 是一个使用地球特定先验知识,在 39 年的全球数据上进行训练的 3 D 深度学习模型,可以生成中期全球天气预报。该系统可以用于更准确地进行早期气旋追踪,相比现有技术有所改进。
- NowcastNet103 是一个非线性模型,使用物理第一原理和统计学习方法,在深度生成模型框架下统一起来。通过中国各地的 62 名专业气象学家的评估,在 71%的情况下,该模型在领先方法中排名第一。


音乐生成
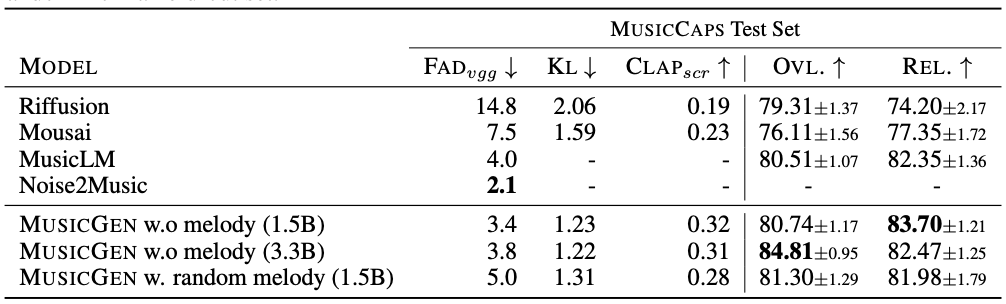
Another year of progress in music generation
来自 Google、Meta 和开源社区的新模型显著提升了可控音乐生成的质量。
- 尽管在生成音乐的质量方面并不是最好的,但 Riffusion104 可能是最具创新性的模型之一。研究人员对 Stable Diffusion 在频谱图像上进行了微调,然后将其转换为音频片段。
- Google 的 MusicLM 将条件音乐生成视为一种分层序列到序列(seq 2 seq)建模任务。它能够在数分钟内生成一致的音乐(@24 kHz)。可以在这里105上找到示例样本。
- 对我们来说,Meta 的 MusicGen 在遵循文本描述和生成愉悦旋律之间取得了更好的平衡。它使用了单个 Transformer 语言模型和精心设计的码本交错技术。样本可以在这里106上找到。
分子生物学与医药研究
Diffusion models design diverse functional proteins from simple molecular specifications
从零开始设计具有所需功能或结构特性的新型蛋白质,即从头设计(de novo design),在研究和工业领域都具有重要意义。受到在图像和语言生成建模方面取得成功的启发,扩散模型现在被应用于从头设计蛋白质工程。
- 一个名为 RFdiffusion 107 的模型利用 RoseTTAFold 在高精度、残基级别分辨率的蛋白质结构预测能力的基础上,将其作为去噪网络在生成式扩散模型中进行微调,使用来自蛋白质数据银行的噪声结构。
- 类似于 AlphaFold 2,RFdiffusion 在模型对先前预测的时间步间进行去噪的条件下进行训练效果最佳。
- RFdiffusion 可以生成具有所需特征的蛋白质骨架,然后可以使用 ProteinMPNN 来设计编码这些生成结构的序列。
- 该模型可以为蛋白质单体、蛋白质结合物、对称寡聚体、酶活性位点支架等生成骨架设计。
Learning the rules of protein structure at evolutionary-scale with language models

现在可以直接根据氨基酸序列预测原子级别的蛋白质结构,而无需依赖昂贵且缓慢的多序列比对(MSA)。为了实现这一目标,使用了掩码语言建模目标,在数百万个进化多样的蛋白质序列上进行训练,使生物结构在语言模型中具现化,因为它与序列模式相关联108 。
- 这个名为 Evolutionary Scale Modeling-2(ESM-2)的模型用于表征超过 617 M 个元基因组蛋白质的结构(发现于土壤、细菌、水等)。ESM-2 相对于 AlphaFold-2(AF 2)具有显著的加速优势:这些结果是在使用 2000 个 GPU 的集群上的 2 周时间内产生的。
- ESMFold 是一个完全端到端的单序列结构预测器,使用 ESM-2 的折叠头。ESMFold 的结构通过与基准真实结构的 TM 分数进行比较,达到了与 AF 2 相当的质量水平。

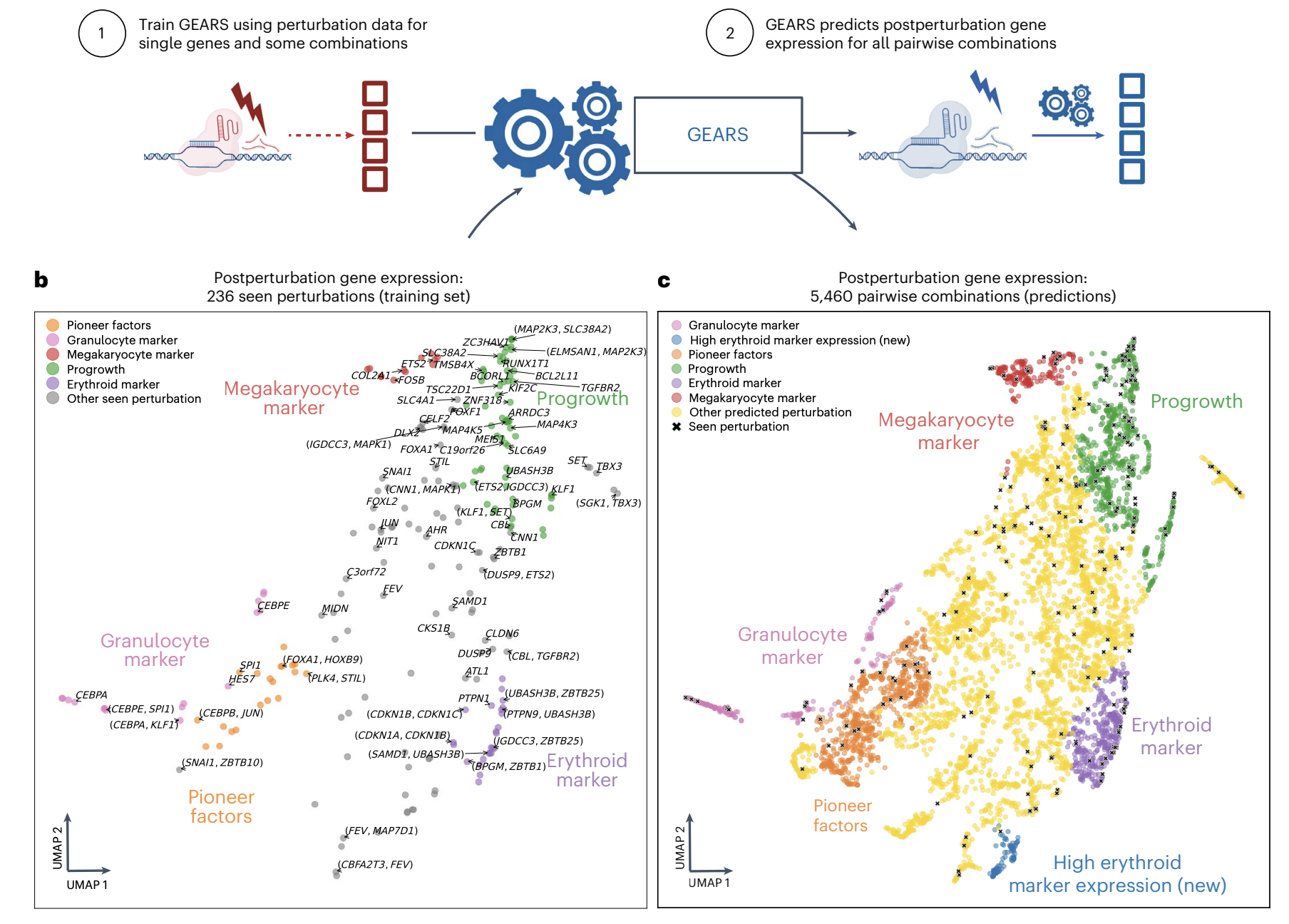
Predicting the outcome of perturbing multiple genes without a cell-based experiment
理解基因组合(即扰动)的刺激或抑制如何导致基因表达的变化对于揭示与健康和疾病相关的生物途径非常重要。但是,由于组合爆炸的原因,我们无法在实验室中的活细胞中运行这些实验。将深度学习与基因关系知识图结合起来提供了一种解决方案。
- 图增强基因激活和抑制模拟器(GEARS)109 结合了先前的实验知识,可以预测在给定未扰动的基因表达和应用的扰动情况下的基因表达结果110。
- 例如,GEARS 可以在单基因和双基因实验的扰动后的基因表达谱上进行训练(b),然后被要求预测 5,460 个成对组合的扰动后基因表达情况(c)。
Pathogenic or not? Predicting the outcome of all single-amino acid changes 病原性还是非病原性?预测所有单氨基酸变化的结果
由基因变异引起的氨基酸序列的个别变化(“错义变异”)可能是良性的,也可能导致蛋白质折叠、活性或稳定性的下游问题。通过人类群体级基因组测序实验,已经确定了超过 4 百万个这样的错义变异。然而,其中 98%的变异缺乏任何经过确认的临床分类(良性/致病性)。一个名为 AlphaMissense 111 的新系统利用 AlphaFold 预测和非监督的蛋白质语言建模来填补这个空白。
- AlphaMissense 系统的构建包括:
- 根据人口频率数据上的弱标签进行训练,避免使用人类注释以避免循环性
- 结合非监督的蛋白质语言建模任务,学习基于序列上下文的氨基酸分布
- 利用 AlphaFold 导出的系统来包含结构上下文。
- 然后,AlphaMissense 用于预测 71 M 个错义变异,饱和了人类蛋白质组。其中,32%可能是致病性的,57%可能是良性的。附加资源包括对 19,233 个经典人类蛋白质进行的全部 216 M 个可能的单氨基酸替换。

Google’s Med-PaLM 2 language model is an expert according to the USMLE
在发布了 Med-PaLM(首个在美国医学执照考试(USMLE)中获得“合格”分数的模型)一年后,Med-PaLM 2112113通过基于 LLM 的改进、医学领域微调和提示策略,在更多数据集上取得了新的最先进结果。在对 1,066 个消费者医疗问题进行的成对排名研究中,通过我们的评估框架,一组医生对 Med-PaLM 2 的回答在九个维度中的八个维度上优于医生的回答。


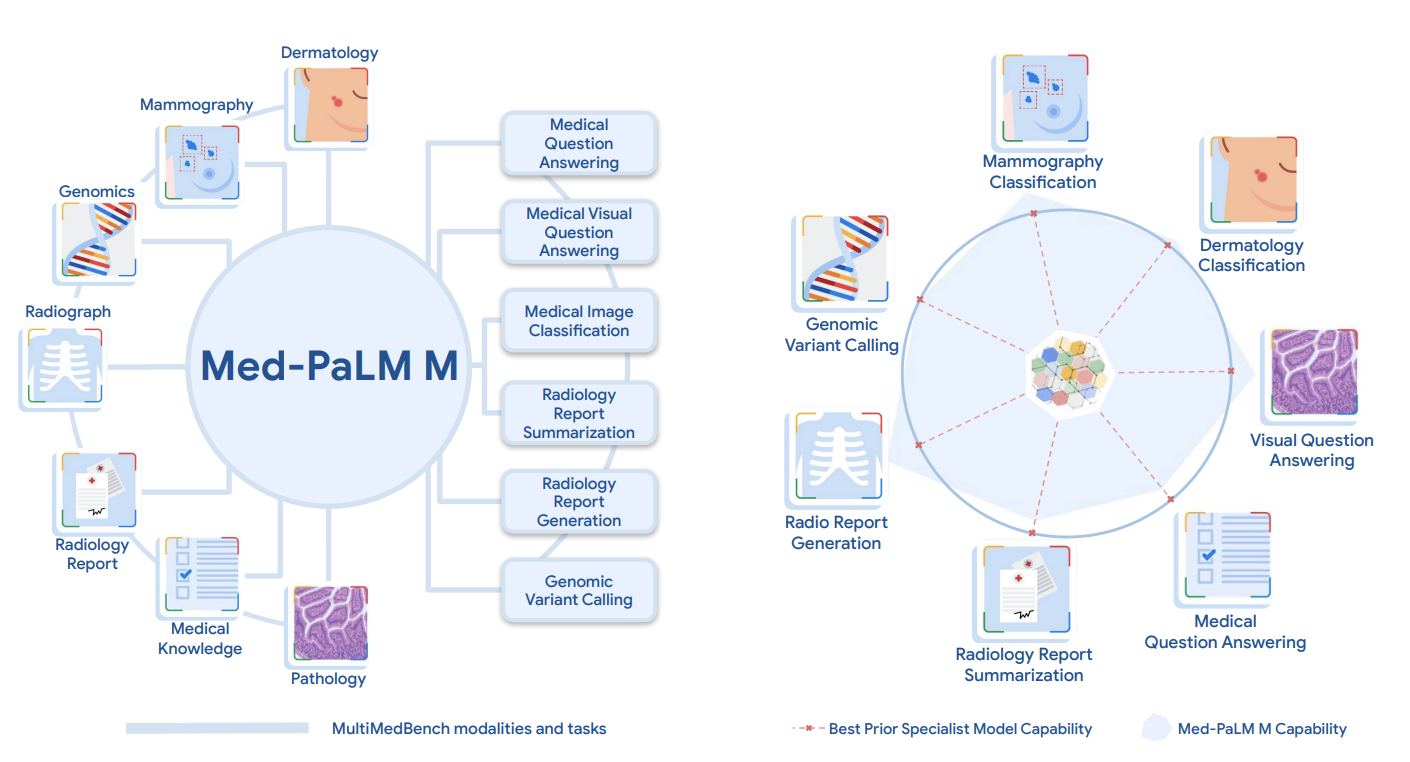
Next, Med-PaLM goes multimodal
为了超越基于文本的医学问答,谷歌首先创建了 MultiMedBench114:一个包含医学问答、乳房 X 光和皮肤科图像解读、放射学报告生成和摘要以及基因组变异调用的 14 个任务数据集。
该数据集用于训练一个大型的单一多任务、多模态版本的 MedPaLM,使用相同的模型权重。该系统展示了对新医学概念和任务的泛化能力等新颖的能力。
另外,还提出了一种轻量级的方法,名为 ELIXR115。ELIXR 将语言对齐的视觉编码器嫁接到一个固定的 LLM 上,需要更少的计算资源进行训练,并在视觉问答、语义搜索和零样本分类等任务上显示出潜力116。

Tweet storm: a SOTA pathology language-image pretrained model from medical Twitter117
众所周知,(优质)数据对于构建功能强大的 AI 系统至关重要,尤其是在临床医学等领域,(优质)数据的生成成本很高。这项工作在 Twitter 上挖掘文本-图像对,创建了包含 200 多个病理图像和自然语言描述的 OpenPath 数据集118。受 OpenAI 的对比性语言-图像预训练(CLIP)模型的启发,作者创建了 P (athology) LIP119。
- 像 CLIP 一样,PLIP 可以对未见数据进行零样本分类,使其能够区分几种关键组织类型。
- 它还可以用于改进病理图像的文本到图像和图像到图像的检索。
- 与数字病理学中其他基于学习固定标签集的机器学习方法不同,PLIP 可以更普遍地应用,并且可以灵活适应病理学诊断标准的变化性质。
- 与 CLIP 相比,PLIP 在 Precision@10 方面提高了 2-6 倍。

Real world-inspired clinical system design for automated medical image analysis
计算机视觉已经显示出在乳腺癌筛查和结核病分流方面非常有用。然而,在临床中实现实际和可靠的应用,重要的是要知道何时依赖于预测性的 AI 模型或回归到临床工作流程。
- 基于互补性的临床工作流程推迟(CoDoC)120 学习决定是依赖于预测性的 AI 模型的输出还是回归到临床工作流程。
- 对于乳腺癌筛查,与英国的双重阅读和仲裁相比,CoDoC 在相同的假阴性率下将假阳性率降低了 25%。重要的是,由此减少了 66%的临床工作负荷。
**
AI for science: medicine is growing fastest but mathematics captures the most attention
将人工智能应用于加速进步的前 20 个科学领域包括物理学、社会学、生命科学和健康科学。在所有领域中,医学的发表数量增长最多。我们预计由于人工智能在科学领域的应用,未来可预见会有重大的研究突破。
**
AI 研究越发集中在少数国家与机构
Most impactful research comes from very few places
在过去 3 年中,超过 70%的被引用最多的人工智能论文的作者来自美国的机构和组织。


编者总结与展望
虽然在过去的一年里面我们面对大模型领域的各种发布已经眼花缭乱,现在回过头来再把他们总结梳理一遍仍然会感到十分震撼。大模型领域的一年内发展可谓是百花齐放,除了广为人知的 ChatGPT、MidJounery 和 GitHub CoPilot 这样普通消费者能够接触到的应用,还有像天气预报、3 D 渲染、分子生物学、具身智能机器人等各种不同领域的进展。虽然这部分关注的都是研究领域的发展,虽然可能他们距离真正的落地还需要更多的时间,毋庸置疑的是大模型确实正在真真切切地改变着很多行业。
本部分的最后一张 slide 总结到:「在过去 3 年中,超过 70%的被引用最多的人工智能论文的作者来自美国的机构和组织」。与美国相比,国内虽然也在突飞猛进地向前发展着,毋庸置疑我们还存在着巨大差距。明显的对比是,除了传统类似于视频图片特效、聊天机器人、下一代搜索这些互联网领域常见应用,美国更快更多地将大模型相关技术与其全世界的生物制药、3 D 渲染、机器人等领域结合,并做出了很多非常棒的工作。
尽管历史上我们确实在生物制药等相关领域存在着巨大差距,但是,每一次新技术的突破都是后来者弯道超车的机会。毕竟,我们不能总是守着「搜广推」,也许接下来的若干年还能继续上演华为 Mate 60 Pro 手机芯片逆袭的故事。期待下一年的 State of AI Report,期待下一个十年,期待中国未来的故事。
State of AI Report 2023 报告第一篇到此技术,后续报告将在明日跟进,或者你也可以直接阅读原文查看原始资料
关于作者 魏后民,本科毕业于北京大学,在字节跳动 AML 从事大规模机器学习系统相关工作。过去曾在腾讯和 Hulu 工作,对 AI Infra 和科技创投感兴趣。欢迎加我的微信 Houmin_Wei 与我交流,请注明个人姓名与从事行业方向以及来意,欢迎加入 In The Loop 科技交流群。
-
State of AI Report 2023, Nathan Benaich, https://docs.google.com/presentation/d/156WpBF_rGvf4Ecg19oM1fyR51g4FAmHV3Zs0WLukrLQ/preview?slide=id.g24daeb7f4f0_0_3373 ↩︎
-
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback, https://arxiv.org/abs/2307.15217 ↩︎
-
The False Promise of Imitating Proprietary LLMs, https://arxiv.org/abs/2305.15717 ↩︎
-
RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback, Anthropic, https://arxiv.org/abs/2309.00267 ↩︎
-
LIMA: Less Is More for Alignment, Meta, https://arxiv.org/abs/2305.11206 ↩︎
-
Large Language Models Can Self-Improve, Google, https://arxiv.org/abs/2210.11610 ↩︎
-
Self-Instruct: Aligning Language Models with Self-Generated Instructions, https://arxiv.org/abs/2212.10560 ↩︎
-
Self-Alignment with Instruction Backtranslation, Meta, https://arxiv.org/abs/2308.06259 ↩︎
-
Stanford Alpaca, https://crfm.stanford.edu/2023/03/13/alpaca.html ↩︎
-
MosaicML MPT-30B, https://www.mosaicml.com/blog/mpt-30b ↩︎
-
TII UAE Falcon, https://falconllm.tii.ae ↩︎
-
Together RedPajama, https://github.com/togethercomputer/RedPajama-Data ↩︎
-
Eleuther Pythia, https://github.com/EleutherAI/pythia ↩︎
-
Adept Persimmon, https://www.adept.ai/blog/persimmon-8b ↩︎
-
Mistral 7B, https://mistral.ai/news/announcing-mistral-7b ↩︎
-
Falcon 180B, https://twitter.com/DrJimFan/status/1699459647592403236 ↩︎
-
LMSYS ORG Vicuna, https://lmsys.org/blog/2023-03-30-vicuna ↩︎
-
Are Emergent Abilities of Large Language Models a Mirage? https://arxiv.org/abs/2304.15004 ↩︎ ↩︎
-
Common arguments regarding emergent abilities, https://www.jasonwei.net/blog/common-arguments-regarding-emergent-abilities ↩︎
-
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning, https://arxiv.org/abs/2307.08691 ↩︎ ↩︎
-
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation, ALiBi, https://arxiv.org/abs/2108.12409 ↩︎
-
RoFormer: Enhanced Transformer with Rotary Position Embedding, RoPE, https://arxiv.org/abs/2104.09864 ↩︎
-
Extending Context Window of Large Language Models via Positional Interpolation, https://arxiv.org/abs/2306.15595 ↩︎
-
Lost in the Middle: How Language Models Use Long Contexts, https://arxiv.org/abs/2307.03172 ↩︎
-
How Long Can Open-Source LLMs Truly Promise on Context Length? https://lmsys.org/blog/2023-06-29-longchat/ ↩︎
-
The case for 4-bit precision: k-bit Inference Scaling Laws, https://arxiv.org/abs/2211.17192 ↩︎
-
Fast Inference from Transformers via Speculative Decoding, https://arxiv.org/abs/2211.17192 ↩︎
-
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient, https://arxiv.org/abs/2301.11913 ↩︎
-
TinyStories: How Small Can Language Models Be and Still Speak Coherent English? https://arxiv.org/abs/2305.07759 ↩︎
-
Textbooks Are All You Need, https://arxiv.org/abs/2306.11644 ↩︎
-
George Hotz: Tiny Corp, Twitter, AI Safety, Self-Driving, GPT, AGI & God | Lex Fridman Podcast, https://youtu.be/dNrTrx42DGQ?si=29E21VkBlmnOoBPV&t=5476 ↩︎
-
https://twitter.com/soumithchintala/status/1671267150101721090 ↩︎
-
GPT-4 Architecture, Infrastructure, Training Dataset, Costs, Vision, MoE, https://www.semianalysis.com/p/gpt-4-architecture-infrastructure ↩︎
-
GPT-4’s Secret Has Been Revealed, https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed ↩︎
-
https://epochai.org/blog/will-we-run-out-of-ml-data-evidence-from-projecting-dataset ↩︎
-
Nougat: Neural Optical Understanding for Academic Documents, https://arxiv.org/abs/2308.13418 ↩︎
-
Synthetic Data from Diffusion Models Improves ImageNet Classification, https://arxiv.org/abs/2304.08466 ↩︎
-
The Curse of Recursion: Training on Generated Data Makes Models Forget, https://arxiv.org/abs/2305.17493v2 ↩︎
-
A Watermark for Large Language Models, https://arxiv.org/abs/2301.10226 ↩︎
-
New tool helps watermark and identify synthetic images created by Imagen, https://www.deepmind.com/blog/identifying-ai-generated-images-with-synthid ↩︎
-
Extracting Training Data from Diffusion Models, https://arxiv.org/abs/2301.13188 ↩︎
-
To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis, https://arxiv.org/abs/2305.13230 ↩︎
-
Scaling Data-Constrained Language Models, https://arxiv.org/abs/2305.16264 ↩︎
-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard ↩︎
-
example for vibes: How to train your own Large Language Models, https://blog.replit.com/llm-training ↩︎
-
Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor, Meta, https://arxiv.org/abs/2212.09689 ↩︎
-
AlphaDev announcement, https://www.deepmind.com/blog/alphadev-discovers-faster-sorting-algorithms ↩︎ ↩︎
-
AlphaZero applications, https://www.deepmind.com/blog/optimising-computer-systems-with-more-generalised-ai-tools ↩︎
-
Dimitris Papailiopoulos’ GPT-4, https://twitter.com/DimitrisPapail/status/1666843952824168465 ↩︎
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models, https://arxiv.org/abs/2305.10601 ↩︎
-
Graph of Thoughts: Solving Elaborate Problems with Large Language Models, https://arxiv.org/abs/2308.09687 ↩︎
-
Automatic Chain of Thought Prompting in Large Language Models, https://arxiv.org/abs/2210.03493 ↩︎
-
Large Language Models Are Human-Level Prompt Engineers, https://arxiv.org/abs/2211.01910 ↩︎
-
Large Language Models as Optimizers, https://arxiv.org/abs/2309.03409 ↩︎
-
How is ChatGPT’s Behaviour Changing over Time? https://arxiv.org/abs/2307.09009 ↩︎
-
Meta Toolformer, https://arxiv.org/abs/2302.04761 ↩︎
-
Auto-GPT, https://github.com/Significant-Gravitas/Auto-GPT ↩︎
-
Voyager: An Open-Ended Embodied Agent with Large Language Models, https://voyager.minedojo.org/ ↩︎
-
Reasoning with Language Model is Planning with World Model, https://arxiv.org/abs/2305.14992 ↩︎
-
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning, https://arxiv.org/abs/2305.15486 ↩︎
-
Neural Module Networks, https://arxiv.org/abs/1511.02799 ↩︎
-
https://www.deepmind.com/blog/robocat-a-self-improving-robotic-agent ↩︎
-
https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/ ↩︎
-
Champion-level drone racing using deep reinforcement learning, https://www.nature.com/articles/s41586-023-06419-4 ↩︎
-
Emergence of Maps in the Memories of Blind Navigation Agents, https://arxiv.org/abs/2301.13261 ↩︎
-
https://ai.meta.com/blog/cicero-ai-negotiates-persuades-and-cooperates-with-people/ ↩︎
-
Slide 33 of State of AI Report 2022, https://docs.google.com/presentation/d/1WrkeJ9-CjuotTXoa4ZZlB3UPBXpxe4B3FMs9R9tn34I/edit#slide=id.g164b1bac824_0_3201 ↩︎
-
InstructPix2Pix, https://www.timothybrooks.com/instruct-pix2pix/ ↩︎
-
Imagen Editor, https://imagen.research.google/editor/ ↩︎
-
3D Gaussian Splatting, https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/ ↩︎
-
ZipNeRF, https://jonbarron.info/zipnerf/ ↩︎
-
MipNeRF260, https://jonbarron.info/mipnerf360/ ↩︎
-
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion, https://ziyaerkoc.com/hyperdiffusion/ ↩︎
-
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures, https://mobile-nerf.github.io/ ↩︎
-
Neuralangelo: High-Fidelity Neural Surface Reconstruction, https://research.nvidia.com/labs/dir/neuralangelo/ ↩︎
-
DynIBaR: Neural Dynamic Image-Based Rendering, https://dynibar.github.io/ ↩︎
-
DreamFusion: Text-to-3D using 2D Diffusion, https://dreamfusion3d.github.io/ ↩︎
-
Score Jacobian Chaining: Lifting Pretrained 2 D Diffusion Models for 3 D Generation, https://pals.ttic.edu/p/score-jacobian-chaining ↩︎
-
RealFusion: 360° Reconstruction of Any Object from a Single Image, https://lukemelas.github.io/realfusion/ ↩︎
-
SKED: Sketch-guided Text-based 3D Editing, https://arxiv.org/abs/2303.10735 ↩︎
-
Instruct-NeRF 2 NeRF Editing 3D Scenes with Instructions, https://instruct-nerf2nerf.github.io/ ↩︎
-
ZeroDepth: Towards Zero-Shot Scale-Aware Monocular Depth Estimation, https://arxiv.org/abs/2306.17253v1 ↩︎
-
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth, https://arxiv.org/abs/2302.12288 ↩︎
-
Google WeatherBench, https://sites.research.google/weatherbench/ ↩︎
-
Pangu-Weather, https://www.nature.com/articles/s41586-023-06185-3 ↩︎
-
NowcastNet, https://www.nature.com/articles/s41586-023-06184-4/figures/4 ↩︎
-
Riffusion, https://www.riffusion.com/about ↩︎
-
Google MusicLM, https://google-research.github.io/seanet/musiclm/examples/ ↩︎
-
De novo design of protein structure and function with RFdiffusion, https://www.nature.com/articles/s41586-023-06415-8 ↩︎
-
Evolutionary-scale prediction of atomic-level protein structure with a language model, https://www.science.org/doi/10.1126/science.ade2574 ↩︎
-
Predicting transcriptional outcomes of novel multigene perturbations with GEARS, https://www.nature.com/articles/s41587-023-01905-6 ↩︎
-
Accurate proteome-wide missense variant effect prediction with AlphaMissense, https://www.science.org/doi/10.1126/science.adg7492 ↩︎
-
Towards Expert-Level Medical Question Answering with Large Language Models, https://arxiv.org/abs/2305.09617 ↩︎
-
Large language models encode clinical knowledge, https://www.nature.com/articles/s41586-023-06291-2 ↩︎
-
Towards Generalist Biomedical AI, https://arxiv.org/abs/2307.14334 ↩︎
-
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders, https://arxiv.org/abs/2308.01317 ↩︎
-
https://www.linkedin.com/posts/christopherkelly1_we-are-excited-to-share-our-latest-work-at-activity-7093185594842849280-FPzL/ ↩︎
-
A visual–language foundation model for pathology image analysis using medical Twitter, https://www.nature.com/articles/s41591-023-02504-3 ↩︎
-
https://twitter.com/james_y_zou/status/1692274709511999935 ↩︎
-
Leveraging medical Twitter to build a visual–language foundation model for pathology AI, https://www.biorxiv.org/content/10.1101/2023.03.29.534834v1.full ↩︎
-
Enhancing the reliability and accuracy of AI-enabled diagnosis via complementarity-driven deferral to clinicians, https://www.nature.com/articles/s41591-023-02437-x ↩︎

alipay

Author houminwei
Publish October 13, 2023
LastMod February 15, 2024
License 本作品采用 CC BY-NC-ND 4.0 许可协议进行许可,转载时请注明原文链接
如果你在浏览博客的过程中发现了任何问题,欢迎在对应文章下评论。如果你有其他事情想要咨询,可以通过邮件联系我。
