当计算撞上通信墙:RDMA 再回首,EtherNET or EtherNOT
在刚刚过去的 AWS re:Invent 2023 上,AWS 进一步发布了 Trainium2、Graviton4 和 Amazon Q 等产品,试图在 Gen AI 狂飙的当下,继续保持其作为全球最大的云计算厂商的领先优势。值得注意的是,这次大会 AWS 最终还是追随了 OCI、Azure 和 Google Cloud 的脚步123,将 NVIDIA 的 DGX Cloud4 引入自家云服务平台5,成为最后一个提供此服务的主要云供应商。众所周知,NVIDIA 当前并不是从零开始构建完整的云基础设施,而是把 DGX Cloud 托管在各家云服务商的云平台上提供服务。也就是说,NVIDIA 将基础硬件设施出售给云厂商,再向他们购买云计算资源,最后把云服务出售给企业客户并自留全部收入。进一步的,因为搭载了 NVIDIA 的 AI Foundations 和 AI Enterprise 等开箱即用的软件平台,DGX Cloud 远比云服务厂商提供的算力服务更加昂贵。云厂商们显然十分明晰 NVIDIA 这般如意算盘,AWS 在年中被曝出明确拒绝了这种商业模式6,半年后,迫于 NVIDIA 的市场地位,AWS 最终还是不得不接受老黄的微笑。
Brown said AWS had declined to work with Nvidia on the DGX Cloud offering. “They approached us, we looked at the business model, and it didn’t make a lot of sense” for AWS due to the company’s long experience in building reliable servers and existing supply chain expertise, Brown said. Brown said that AWS prefers to design its own servers from the ground up.6

然而,AWS 作为全球最大的云厂商还是有着自己的倔强,相较于 Azure 等直接采用 NVIDIA 的 InfiniBand 网络,Azure 选择了自己基于 SRD 自研的 EFA 高速网络实现多节点之间互联。
AWS and NVIDIA connect 32 Grace Hopper Superchips in each rack using a new NVLink switch. Each 32 GH200 NVLink-connected node can be a single Amazon EC2 instance. When these are integrated with AWS Nitro and EFA networking, customers can connect GH200 NVL32 instances to scale to thousands of GH200 Superchips
With AWS Nitro, that becomes basically one giant virtual GPU instance, Huang said.5
是的,GPU 的算力固然重要,数据中心中的网络互联是另一个价值高地,AWS 不愿意也不想将这部分的利润也送到手握 InfiniBand 和 NVLink Network 的 NVIDIA。不仅仅是 AWS,面对人工智能和高性能计算给网络带来的挑战,整个业界都在探索在 Infiniband 和 NVLink 之外新的解决方案。

在前两篇聊完当前大模型对于算力与内存的需求之后,本文尝试深入到网络,从分布式并行训练入手,探讨当前大模型对于网络互联的需求。试图去理解,在 Infiniband 和 RoCE 网络的基础上,目前快速演进与发展的基础网络。在正式开始之前,推荐阅读前置文章:
TLDR
- 本文所有的资料来自于互联网公开信息,更多是从程序员的角度去理解现代高速网络的发展与演变,强烈推荐大家阅读本文附录的原始资料,文中的观点与本人雇主无关。
- 作为一名软件工程师,本文作者对于网络的理解也并不算深刻与全面,甚至可能会存在偏差与错误,在介绍相关方向的时候也肯定会存在遗漏,欢迎交流与指正。
- 本文相对较长,全文超过 10000 字,阅读预计需要 30 分钟左右。建议关注、收藏后观看,也可访问我的博客获得更好阅读体验 https://loop.houmin.site/context/ib2nvlink 。
Technical Terms
在真正开始之前,这里先简单介绍下本文可能会碰到的技术缩略语,现在不需要深刻理解其含义,只需要有初步印象即可。
| 英文 | 缩写 | 释义 |
|---|---|---|
| SHARP | Scalable Hierarchical Aggregation and Reduction Protocol | 可扩展分层次聚合和归约协议,NVIDIA 推出的一种高性能集合通信协议,将聚合操作卸载到交换机,消除多次传输数据的需要 |
| DMA | Direct Memory Access | 直接存储器访问,而不经过 CPU 处理 |
| RDMA | Remote Direct Memory Access | 一种高带宽、低延时的高速通信网络协议,Bypass Kernel,包括 Infiniband 和 RoCEv2 |
| InfiniBand | - | 一种专为 RDMA 设计的网络,需要整套的交换机和以太网卡,由 IBTA 提出 |
| RoCE | RDMA over Converged Ethernet | 基于融合以太网的 RDMA 技术,将早期只在 Infiniband 上能够支持的 RDMA 推广到以太网 |
| NCCL | NVIDIA Collective Communications Library | NVIDIA 推出的集合通信库,专门针对 NVIDIA GPU 和网络适配 |
| ZeRO | 零冗余优化器 | 一种针对大规模分布式深度学习的新型内存优化技术 |
| DPU | 数据处理器 | NVIDIA 提出的用于分担数据中心中虚拟化、安全、存储等功能的芯片,典型代表是 BlueField,Intel 有对应的叫做 IPU,阿里则有 CIPU,以前也有类似的 SmartNIC 的概念 |
| FPGA | 现场可编程门电路 | 一种可编程逻辑器件,相对于 ASIC 而言更灵活 |
| CXL | Compute Express Link | 一种新型的高速互联技术,旨在提供更高的数据吞吐量和更低的延迟,与 PCIe 兼容 |
| PCIe | Peripheral Component Interconnect Express | 一种用于连接计算机内部组件的标准接口技术 |
| IBTA | InfiniBand Trade Association | Infiniband 协议联盟,共同制定 Infiniband 的规范 |
| UEC | Ultra Ethernet Consortium | 超级以太网联盟,试图基于 Ethernet 构建面向 AI 和 HPC 的高性能网络 |
| AOC | Active Optical Cable | 有源光缆,实现内部电-光-电转换,广泛用于数据中心高速传输 |
| DAC | Direct Attach Copper | 直连铜缆,纯电信号,无光电转换过程,兼容性好,但是传输距离短 |
并行训练需要多大的通信量
如前所述,大模型分布式训练往往需要上千乃至上万 GPU 卡进行超大规模并行训练,是典型的计算密集型和通信密集型场景。本节将详细阐述当前应用广泛的典型并行训练方法,并分析其对于网络带宽的巨大挑战。如果你对于并行模式已经十分了解,或者缺乏相关背景,可以直接跳到 Hybrid Parallel 查看并行训练对于网络的需求总结。
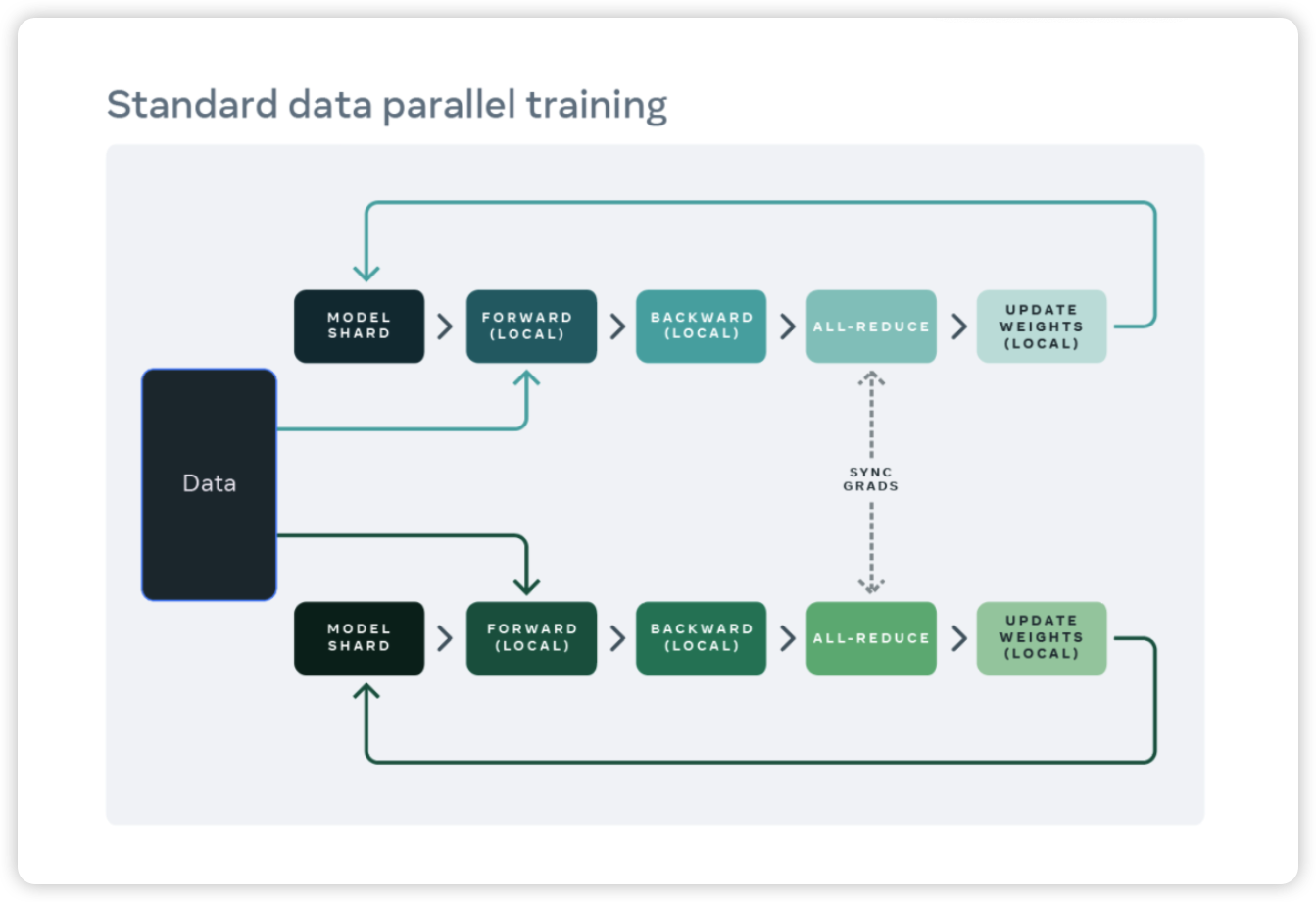
Data Parallel
数据并行是应用最为广泛的并行策略,每个 GPU 都有相同的 model shard,数据集则拆分成多份给到不同的 GPU 进行训练。每一轮迭代训练完成后,每个 GPU 需要把各自反向计算得到的梯度通过 all-reduce 同步。同步完成后,每个 GPU 在本地根据同步后的梯度更新本 GPU 上的模型权重。
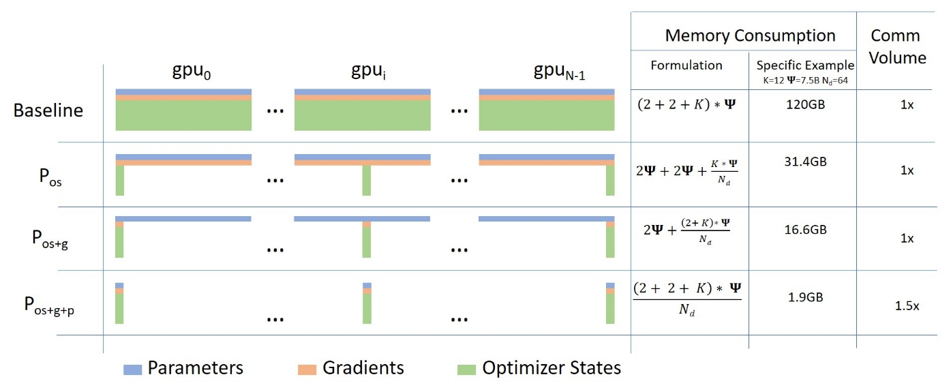
然而,对于现在动辄上千亿参数的语言模型,GPU 当前的显存也已经放不下整个模型权重、梯度和优化器状态。为了解决这个问题,微软提出了 ZeRO7 ,每个 GPU 不再复制完整的模型参数、梯度和优化器状态,而是只存储其中的一部分。
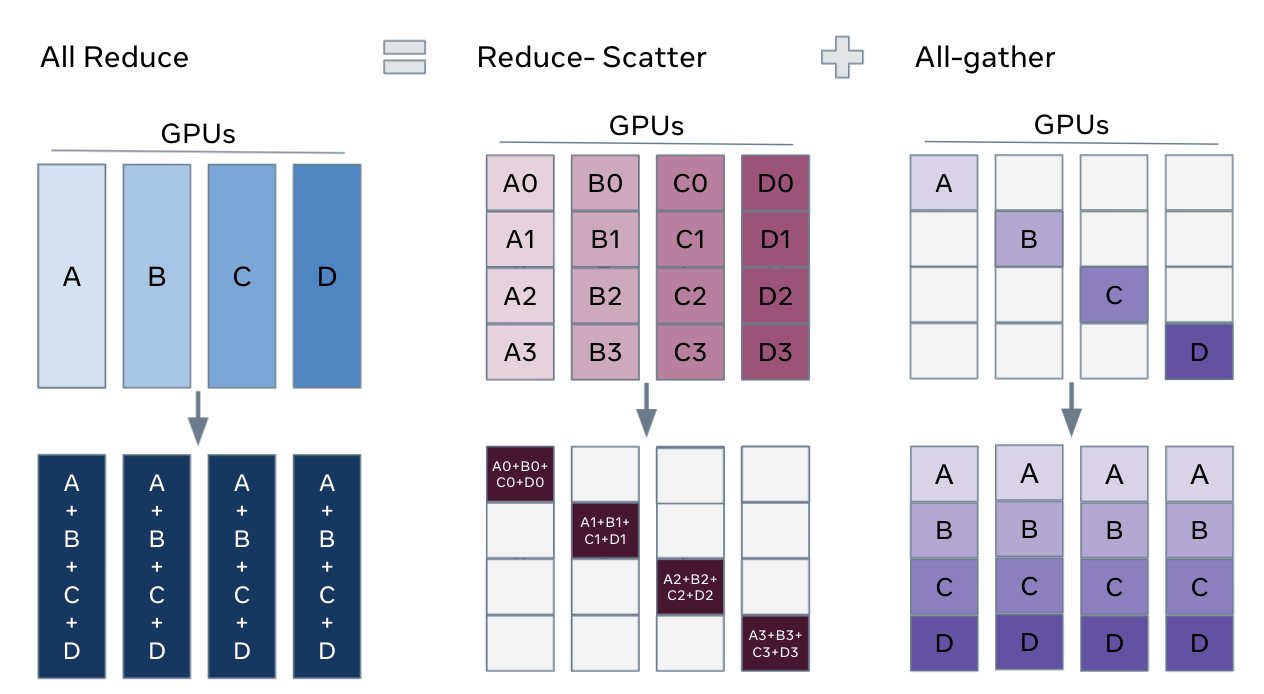
这里实现 full parameter sharding 的关键是,我们可以把数据并行的 all-reduce 拆分成 reduce-scatter 和 all-gather 两个部分8。
对应到训练过程,每个 GPU 只存模型的部分 shard,训练时:
- forward pass 中先通过 all-gather 将模型参数聚集到每个 GPU,然后进行前向计算
- backward pass 也是先通过 all-gather 将模型参数聚集到每个 GPU,然后计算出本地梯度之后,讲过 reduce-scatter 将平均后的梯度分摊在各自 GPU 上,然后进行本地的权重更新

对应的伪代码如下所示:
|
|
这即是 PyTorch FSDP 中 FULL_SHARD 的 Sharding 策略,对应于 ZeRO-3,如下图所示:
FULL_SHARD: Parameters, gradients, and optimizer states are sharded. For the parameters, this strategy unshards (via
all-gather) before the forward, reshards after the forward, unshards before the backward computation, and reshards after the backward computation. For gradients, it synchronizes and shards them (viareduce-scatter) after the backward computation. The sharded optimizer states are updated locally per rank.9
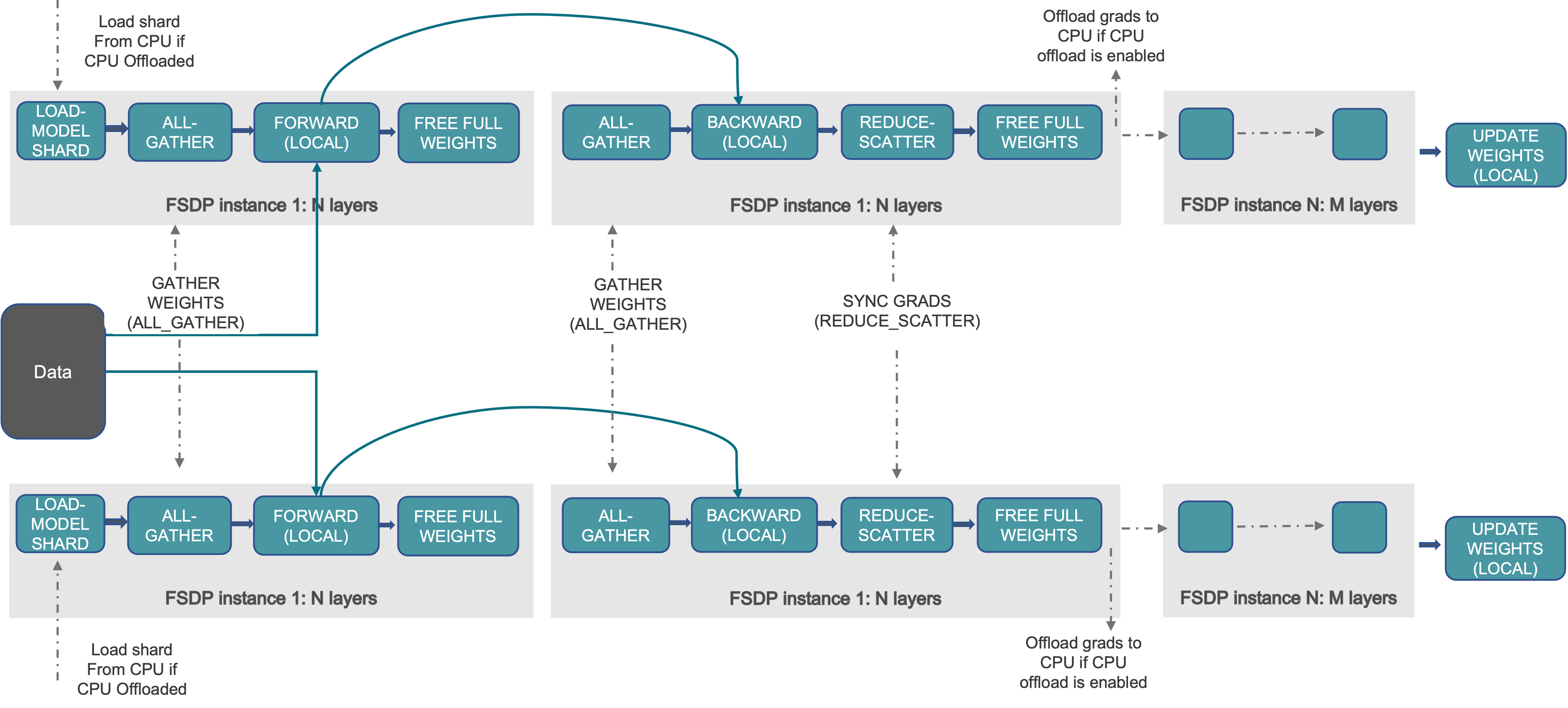
在数据并行中,网络上需要对各个 GPU 上的梯度做一次 Allreduce,通信的数据量规模和模型参数规模成正比,对于千亿规模参数的大模型来说数据通信量都是很大的。

Tensor Parallel
张量并行和流水线并行一样,都属于模型并行,把模型参数和计算分割到多个 GPU 上。与流水线不同,张量并行专注于分解模型的张量,而不是按层切分。
对于矩阵乘法 $Y = XA$,可以按照行来切分,如下所示:
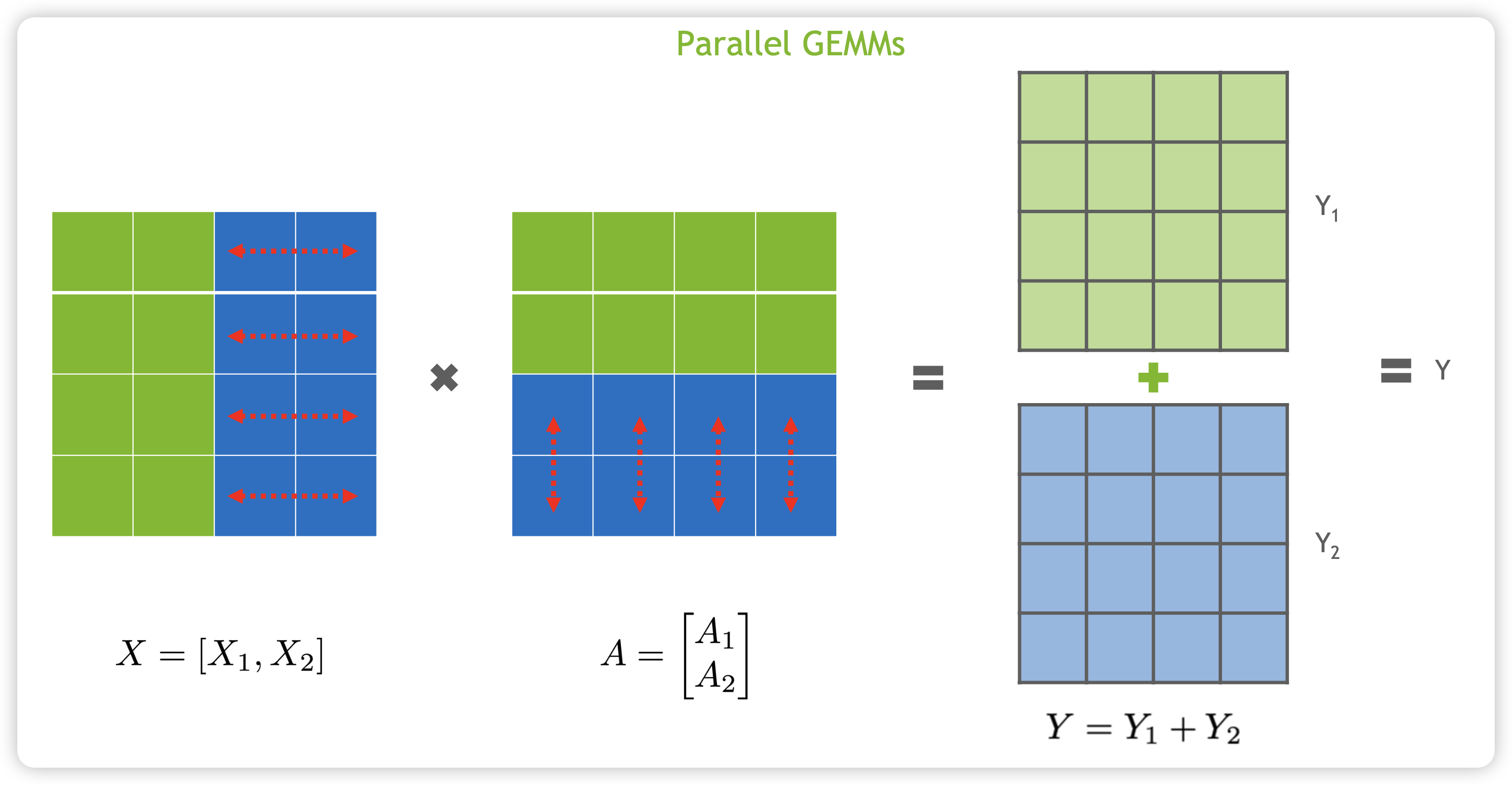
$$ XA = [X_1, X_2]\begin{bmatrix} A_1 \ A_2 \end{bmatrix} = X_1A_1 + X_2A_2 = Y_1 + Y_2 $$
也可以按照列来切分,如下所示:
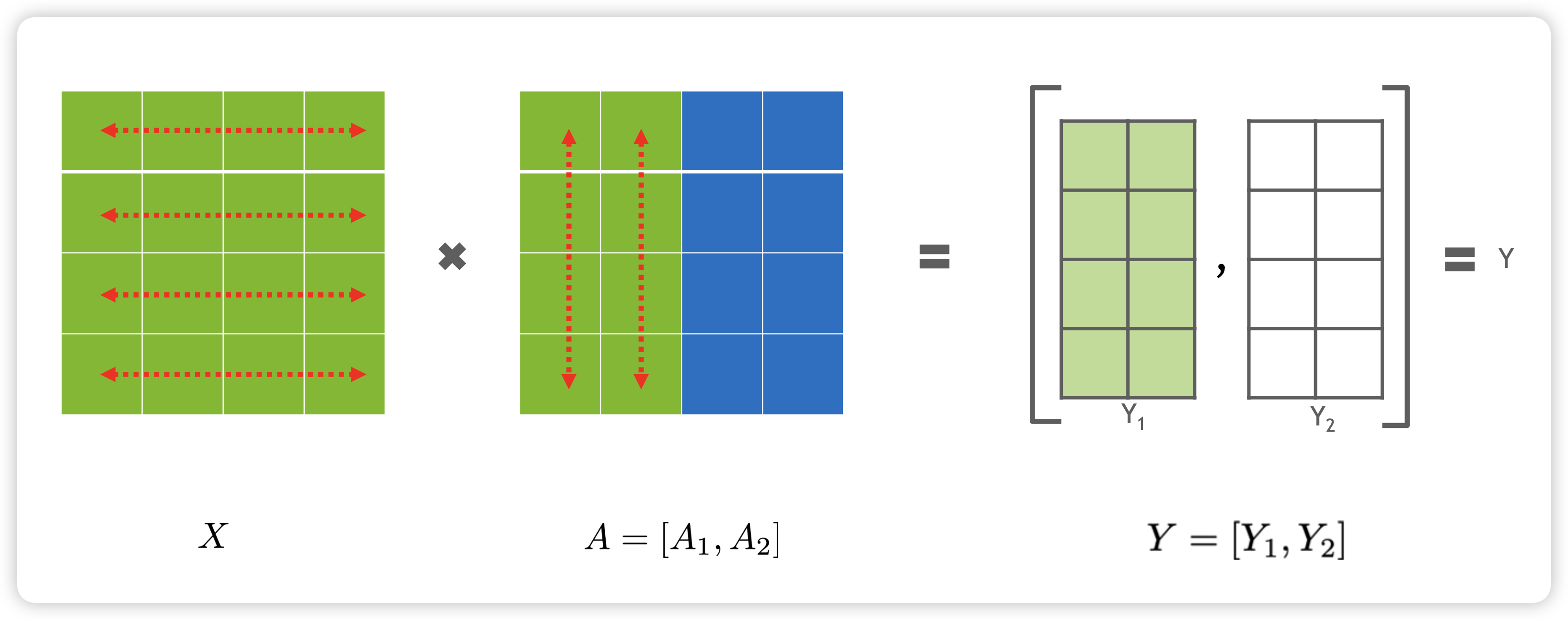
在神经网络中,如果我们认为 X 是输入矩阵,A 是权重矩阵。对应于按行切分 A 矩阵,前向和反向如下所示:
- Row Parallel 前向
- $X$ 输入处需要一个 $f$ 算子,前向的时候将 $X$ 按列切分 split
- 切分后的 $X$ 变成 $X_1$ 和 $X_2$,分别和按行切分后的 $A_1$ 和 $A_2$ 做矩阵乘法
- 输出的 $Y$ 需要经过 $g$ 算子将 $Y_1$ 和 $Y_2$ 做
all-reduce而来
- Row Parallel 反向 - 计算损失 Loss 分别对 Y 的梯度 $\frac{\partial L}{\partial Y_i} = \frac{\partial L}{\partial Y} * \frac{\partial Y}{\partial Y_i} = \frac{\partial L}{\partial Y}$ - 因此只需要把 $\frac{\partial L}{\partial Y}$ 同时广播到两块 GPU,则可以分别独立计算各自权重的梯度,也即 $g$ 是一个 identity 算子 - 计算损失 Loss 分别对输入 $X_i$ 的梯度 $\frac{\partial L}{\partial X_i} = \frac{\partial L}{\partial Y} * \frac{\partial Y}{\partial Y_i} * \frac{\partial Y_i}{\partial X_i} = \frac{\partial L}{\partial Y} * \frac{\partial Y_i}{\partial X_i}$ ,也即是 $\frac{\partial L}{\partial X} = concat(\frac{\partial L}{\partial X_1}, \frac{\partial L}{\partial X_2})$ - 因此 $f$ 是 all-gather 算子
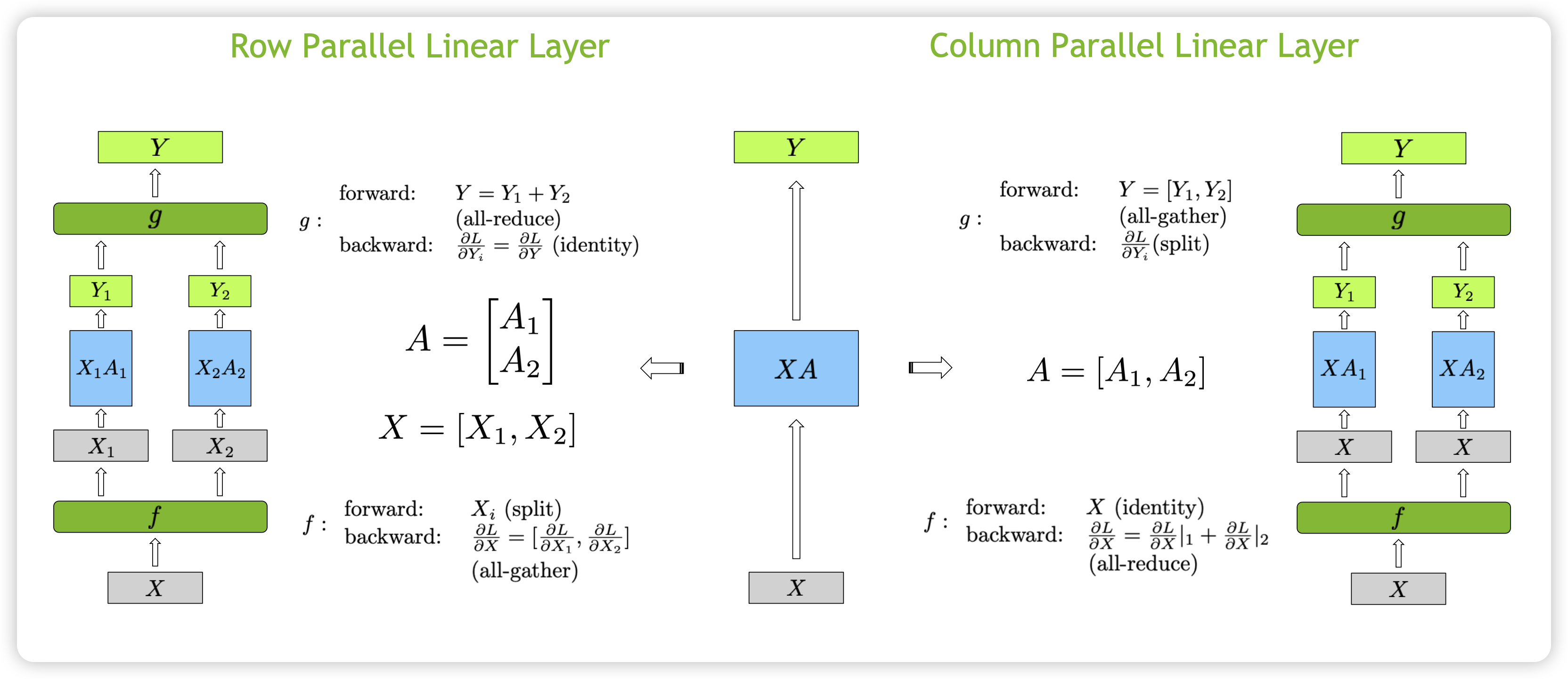
对应于和按列切分 A 矩阵,前向和反向如下所示:
- Column Parallel 前向
- 按列拆分 $A$ 矩阵, $X$ 不需要拆分,因此 $f$ 算子为 identity
- $X$ 分别和切分后的 $A_1$ 和 $A_2$ 做矩阵乘法,得到 $Y_1$ 和 $Y_2$
- 输出的 $Y$ 需要经过 $g$ 算子将 $Y_1$ 和 $Y_2$ 拼接起来,也就是 all-gather
- Column Parallel 反向
- 计算损失 Loss 分别对 Y 的梯度 $\frac{\partial L}{\partial Y_i}$,因为 Y 为 $Y_1$ 和 $Y_2$ 拼接而来,因此 $g$ 为 split 算子
- 因为 X 既参与了对 $XA_1$ 的计算,也参与了对 $XA_2$ 的计算,因此 $\frac{\partial L}{\partial X} = \frac{\partial L}{\partial X}|_1 + \frac{\partial L}{\partial X}|_2$
- 也即是 $f$ 是 all-reduce 算子
回来 Transformer 架构,对于 MLP 层,其计算如下,其中 A 维度为 (h, 4h),B 维度为 (4h, h)
$$ Y = GeLU(XA) $$
$$ Z = Dropout(YB) $$
我们采用对 A 按列切分,对 B 按行切分,如下所示:
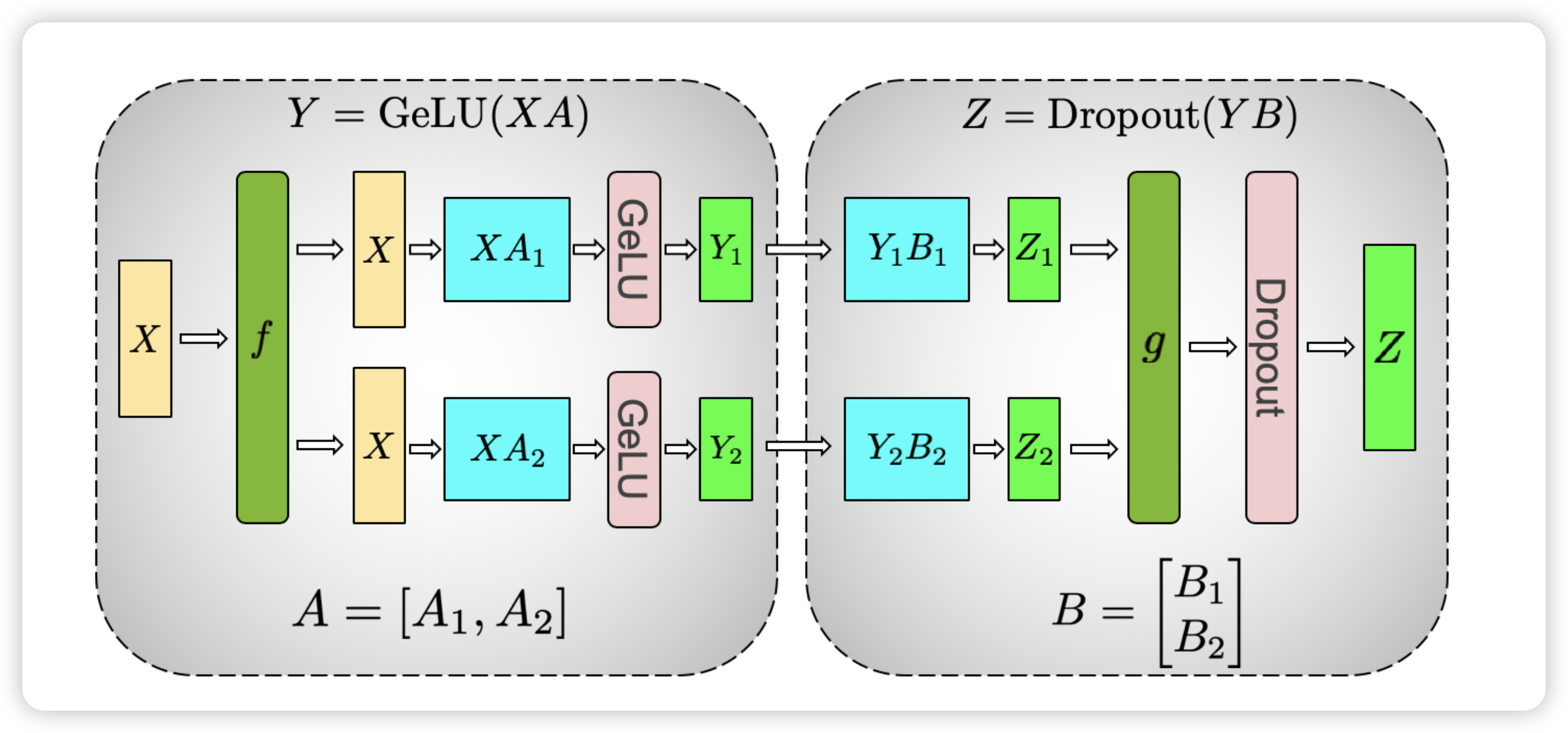
为什么我们对 A 采用列切割,对 B 采用行切割呢?这是为了尽量保证各个 GPU 上计算相互独立,减少通信量。回顾一下 MLP 的结构,两个全连接层中因为有一个 GeLU 非线性函数,如果我们按行切分 A,那么需要在 GeLU 前做 All-Reduce,这将会产生额外的通信量。
跟之前一样,这里的 $f$ 和 $g$ 为共轭算子:
- 前向中,$f$ 为 identity 算子,$g$ 为 all-reduce 算子
- 反向中,$f$ 为 all-reduce 算子,$g$ 为 identity 算子
对于 Self-Attention 层,Multi-Head 天然适合于张量并行,原来的 $Q$ 矩阵 $K$ 矩阵和 $V$ 矩阵的维度为 (hidden size, hidden size) ,假设有 $n_{head}$ 个头,那么每个 head 的矩阵维度为 (hidden size, hidden size//n_head),这即是对于 $QKV$ 矩阵按照列来切分。也就是说,我们可以把每个 head 的矩阵放在一个 GPU 上。对于后续的全连接层,则按照行来切分。
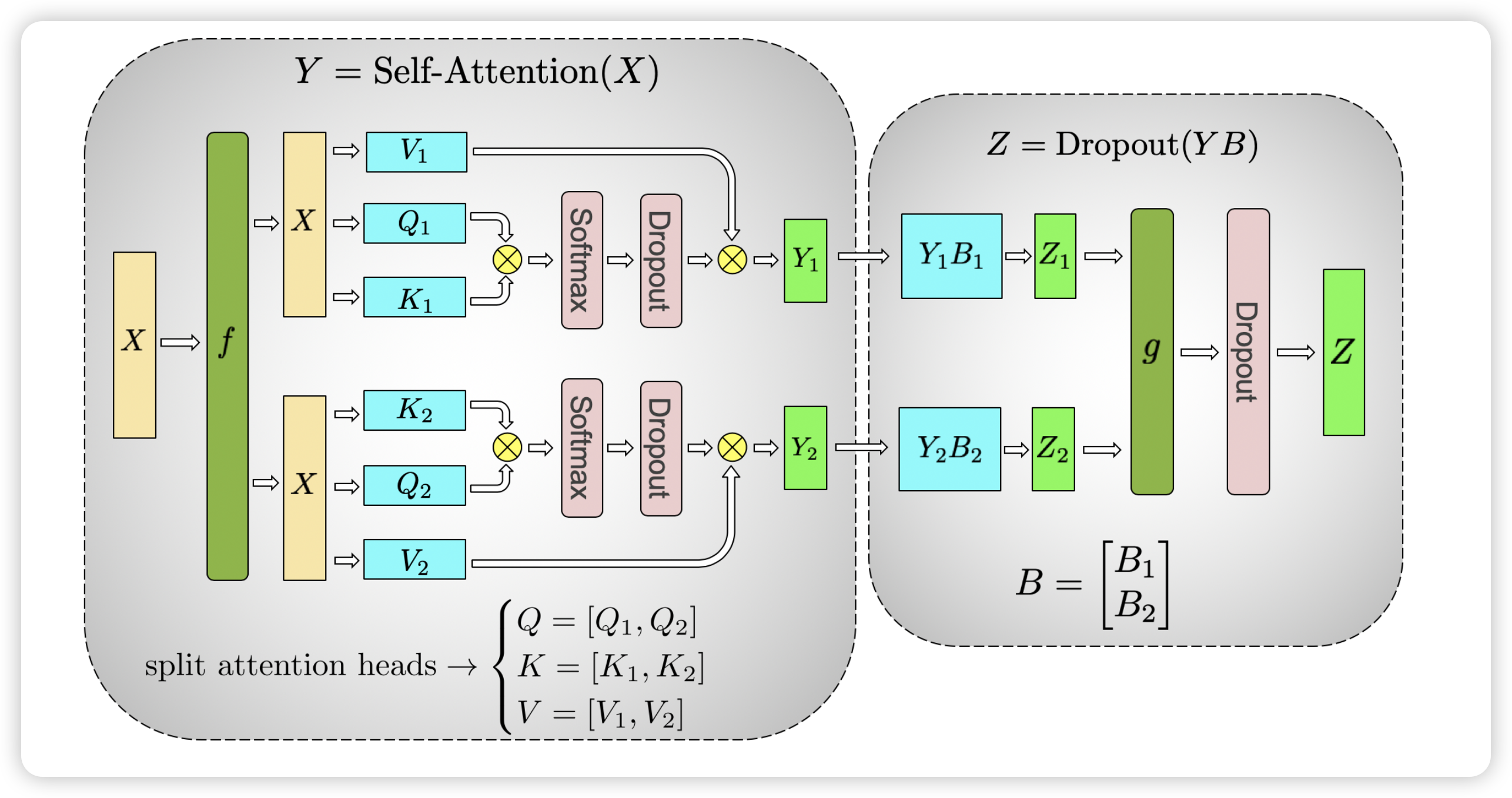
跟之前一样,这里的 $f$ 和 $g$ 为共轭算子:
- 前向中,$f$ 为 identity 算子,$g$ 为 all-reduce 算子
- 反向中,$f$ 为 all-reduce 算子,$g$ 为 identity 算子
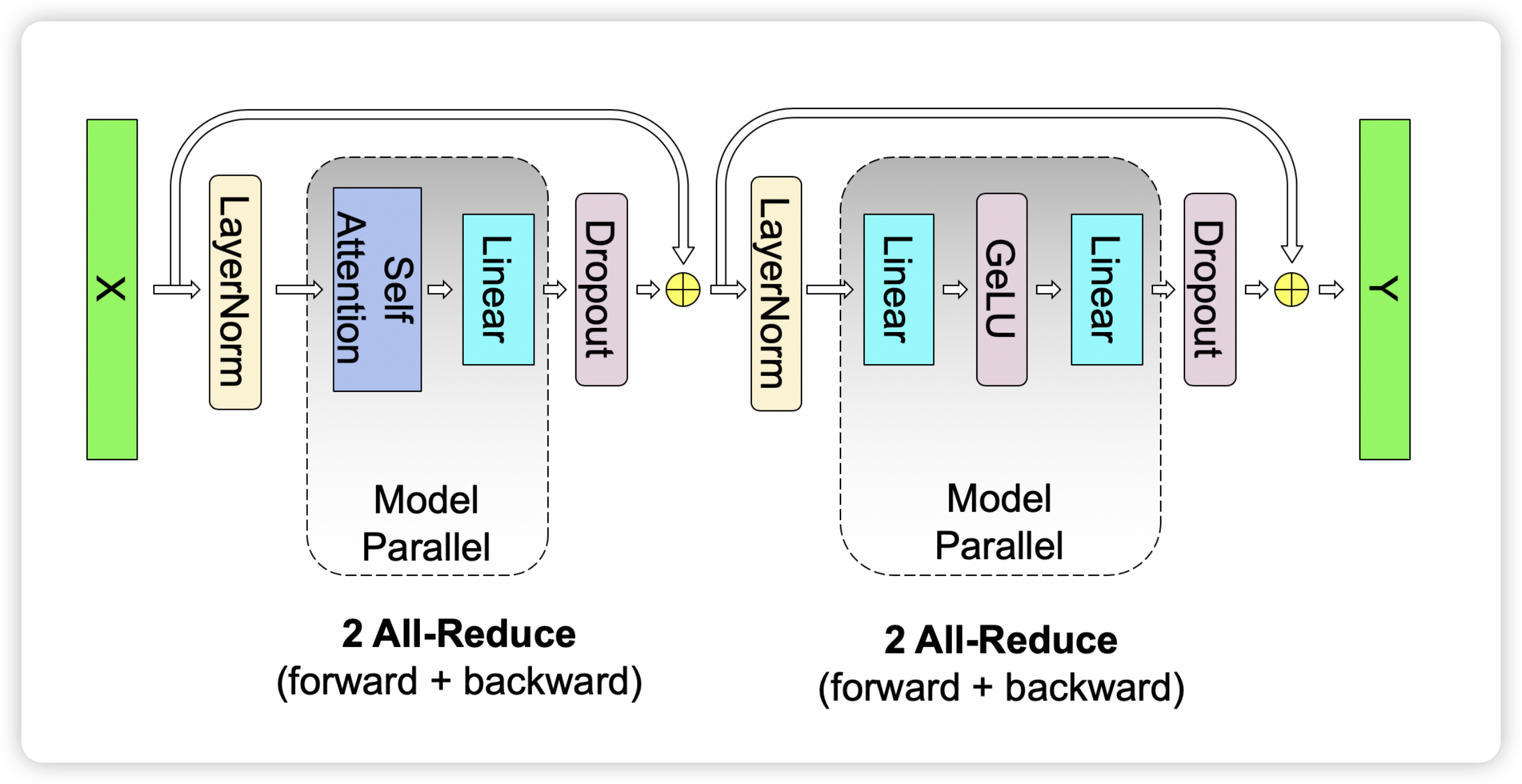
把每一层的 MLP 和 Self-Attention 放在一起,如下所示,对于 transformer 的每一层,前向需要多的两次 all-reduce,反向也需要多增加两次 all-reduce
Sequence Parallel
在 Tensor Parallel 之前,每一层 Transformer 激活的显存占用为 $sbh (34+5*\frac{as}{h})$,这里的符号表示与 Megatron 论文中保持一致。
- Layer Norm 的输入: $2sbh$
- Self Attention 的输入: $2sbh$
- QKV 各自都需要保存: $2sbh\times3$
- QK 结果 Softmax:$2as^2b$
- Softmax 的 dropout mask 和 dropout 之后的输出:$as^2b + 2as^2b$
- 线性层的输入和 dropout mask: $2sbh + sbh$
- Layer Norm 的输入: $2sbh$
- 两个 MLP 的输入: $2sbh + 8sbh$
- GeLU 的输入: $8sbh$
- Dropout: $sbh$
Tensor Parallel 可以将训练中的计算分摊到多个 GPU 上,同时也减少了每个 GPU 上的显存占用。开启 Tensor Parallel 之后,Attention 和 MLP 等部分的显存可以被分摊到不同的设备上,但是仍然有以下两个部分不能被分摊:
- 两个 LayerNorm 层的输入与输出: $2sbh\times2\times2$
- 两个 Droupout mask: $2sbh$
因此开启 Tensor Parallel 之后,每一层 Transformer 激活的显存占用为 $sbh (10+\frac{24}{t} + 5*\frac{as}{ht})$ 。如下图所示,这即是论文 Reducing Activation Recomputation in Large Transformer Models10 中的 baseline。
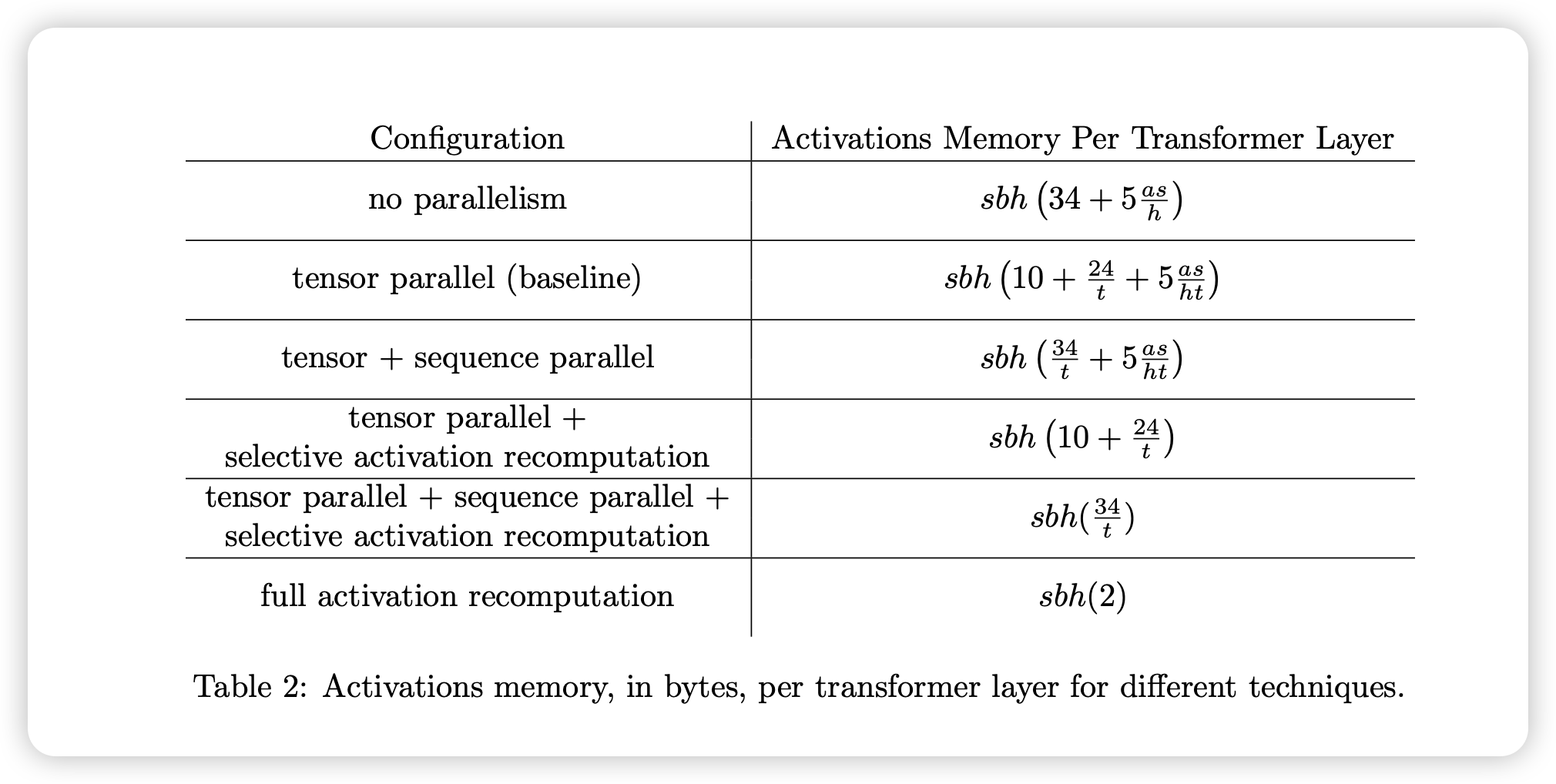
可以看到,即是使用了 Tensor Parallel,对不同大小的模型,每个 GPU 上 activation 占据的内存依然占很大比例。为了进一步优化显存占用,提高并行计算效率,Megatron 进一步提出 Sequence Parallel。
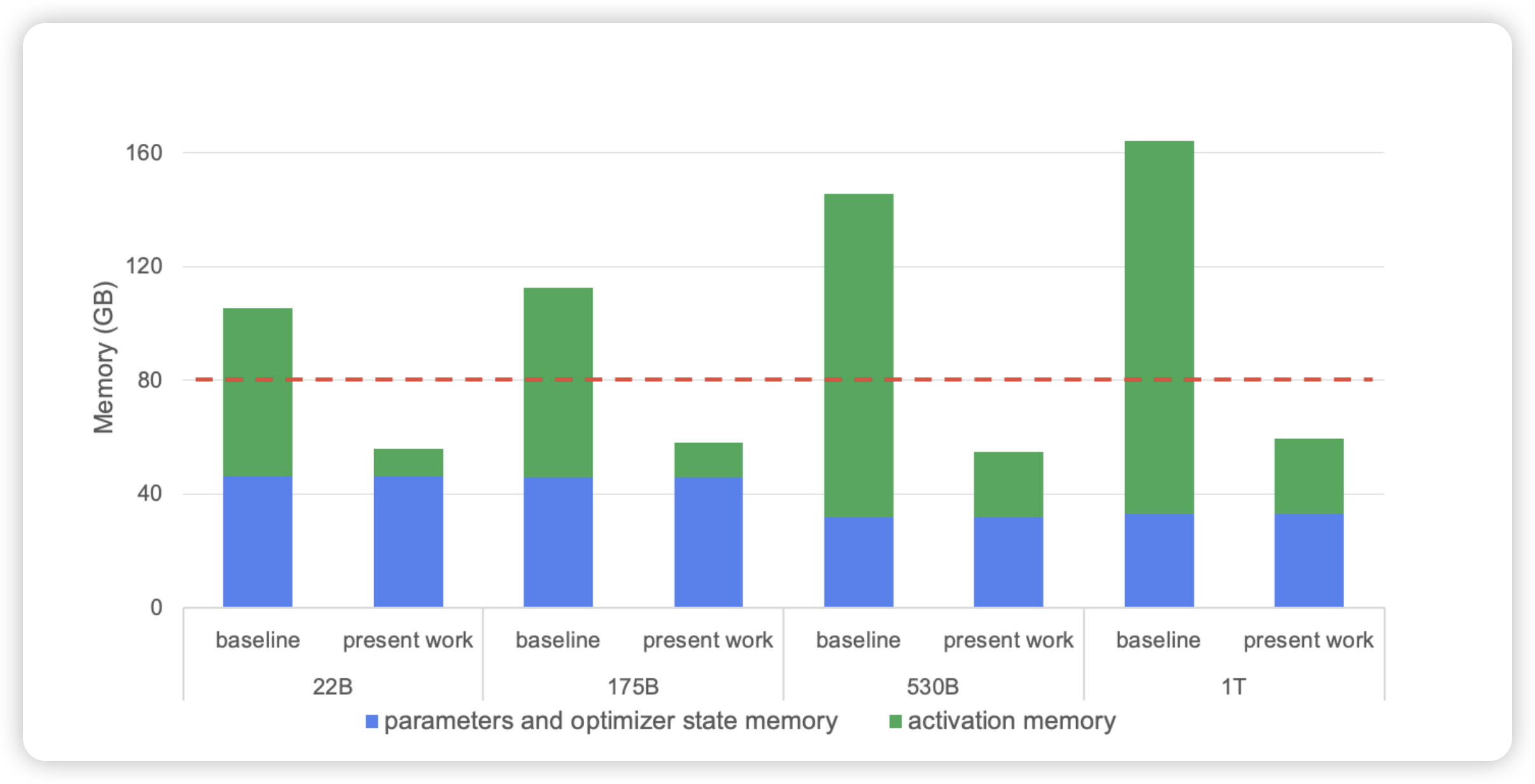
Sequence Parallel 基于 Tensor Parallel,进一步将 LayerNorm 和 Dropout 的输入在 Sequence 维度做了切分,切分数量等于 Tensor Parallel 的并行数量。这样使得每个 GPU 设备只需要做一部分 LayerNorm 和 Dropout 即可,整体上在数学上与原来等价。这样 LayerNorm 和 Dropout 的计算被继续分摊在多个设备上,同时也减少了每个 GPU 上的显存占用。进一步使用 Sequence Parallel 之后,每一层 Transformer 激活的显存占用为 $sbh (\frac{34}{t} + 5*\frac{as}{ht})$
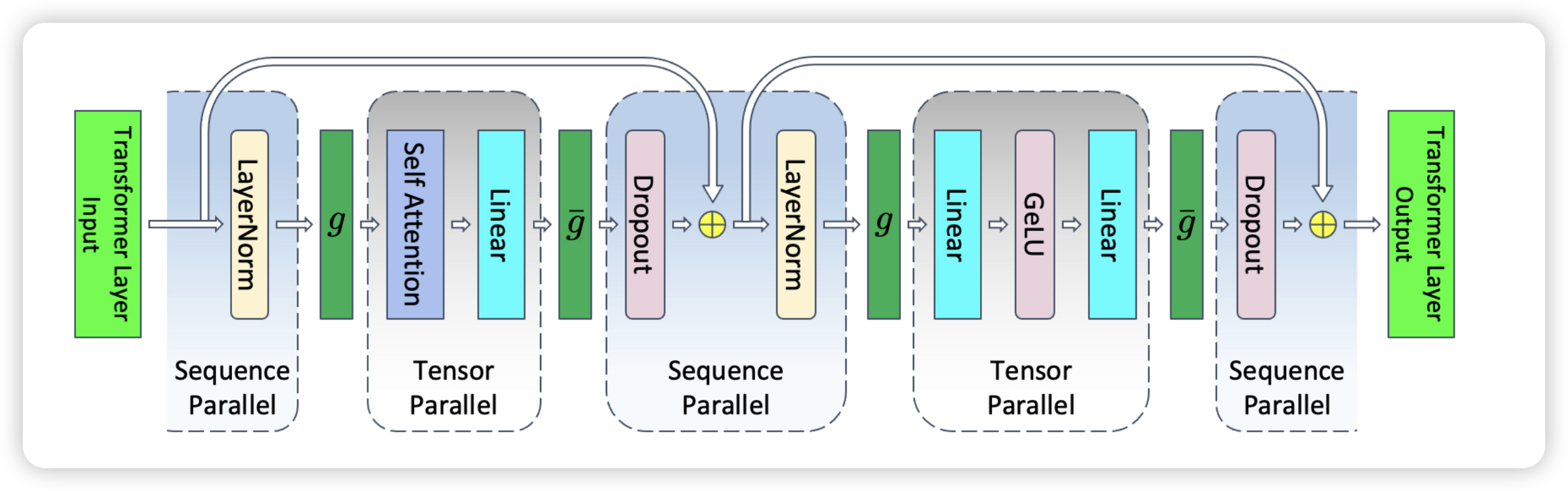
使用 Sequence Parallel 之后,原来每一层在前向和反向的两次 all-reduce 通信模式也需要同步改变。下面以 MLP 层推到上图中具体的 $g$ 和 $\overline{g}$ 语义,Self-Attention 层推导也基本相同。回顾一下 MLP 层的计算过程,如下所示:
$$ Y = LayerNorm(X) $$
$$ Z = GeLU(YA) $$
$$ W = ZB $$
$$ V = Dropout(W) $$
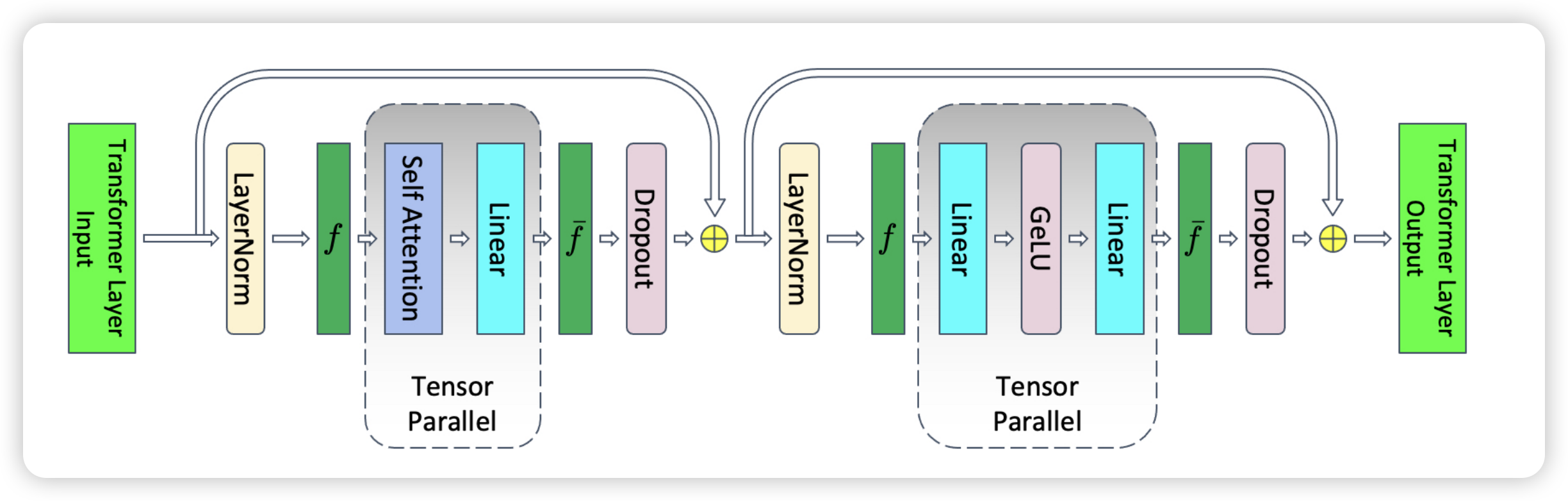
使用 Tensor Parallel 和 Sequence Parallel 之后,计算被拆成以下模式:
$$ [Y_1^s, Y_2^s] = LayerNorm([X_1^s, X_2^s]) $$
$$ Y = g(Y_1^s, Y_2^s) $$
$$ [Z_1^h, Z_2^h] = [GeLU(YA_1^c), GeLU(YA_2^c)] $$
$$ [W_1^s, W_2^s] = \overline{g}(W_1, W_2) $$
$$ [V_1^s, V_2^s] = [Dropout(W_1^s), Dropout(W_2^s)] $$
其中:
- $X_1^s$ 是 $X$ 按照 sequence 维度切分后在 GPU 1 设备上的部分
- $Y_1^s$ 是 $X_1^s$ 在 GPU 1 上计算完 LayerNorm 的结果
- 因为线性层以及 GeLU 要求输入完整的 $Y$,所以这里需要通过 $g$ 算子做
all-gather - 经过
all-gather之后 $Y$ 与 $A_1^c$ ,也就是 $A$ 矩阵在 Column 切分之后计算并通过 GeLU 得到 $Z_1^h$ - $Z_1^h$ 继续和 $B_1^r$,也就是 $B$ 矩阵在 Row 切分后计算得到 $W_1$
- 在 Tensor Parallel 中,$W_1$ 和 $W_2$ 经过一个
all-reduce之后 $W$ 矩阵进行 Dropout 即得到输出,但是 Sequence Parallel 会进一步切分来在多个设备上分别计算 Dropout,因此这里的 $\overline{g}$ 算子为reduce-scatter,这样每个 GPU 都有按照 sequence 维度切分后 $W_1^s$ 进一步计算 Dropout 得到最终的 $V_1^s$
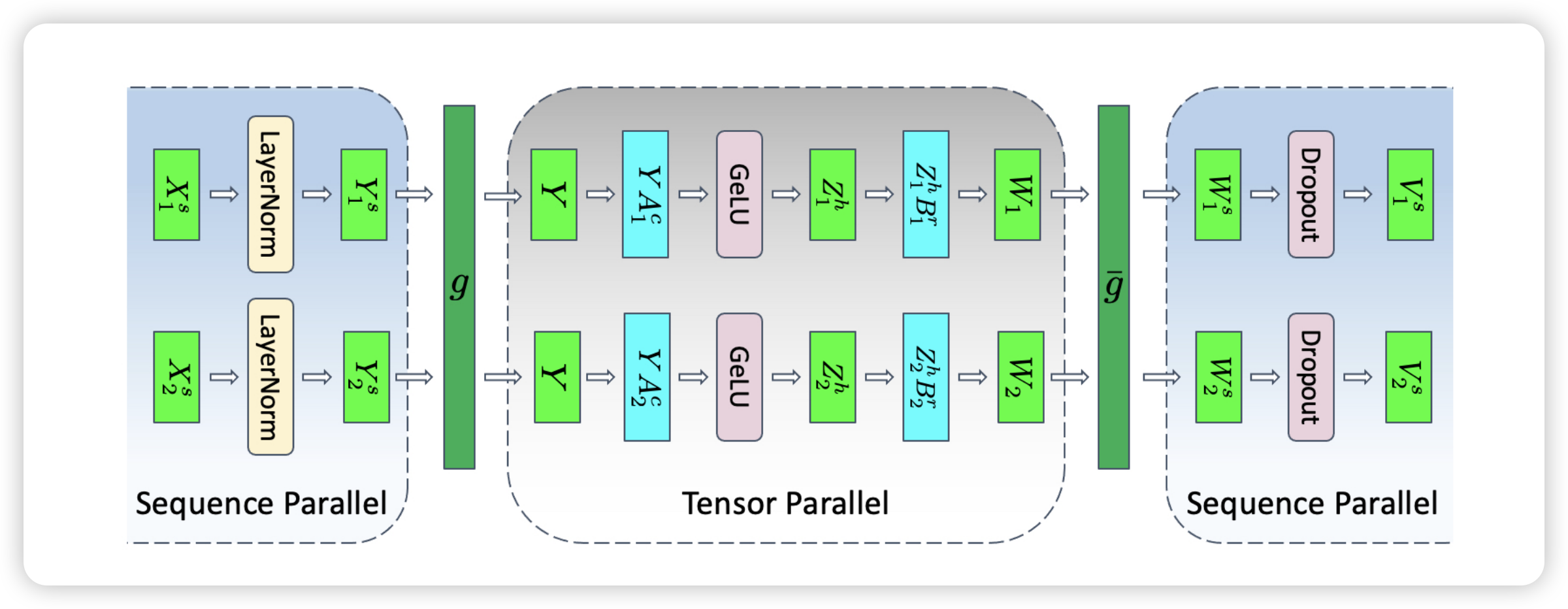
总结一下,使用 sequence parallel 之后,前向和反向分别需要两个 $g$ 算子和两个 $\overline{g}$ 算子:
- 前向:
- $g$ 需要做
all-gather - $\overline{g}$ 需要做
reduce-scatter
- $g$ 需要做
- 反向
- $g$ 需要做
reduce-scatter - $\overline{g}$ 需要做
all-gather
- $g$ 需要做
因为 all-reduce 一般等价于一个 reduce-scatter 和 all-gather,所以 tensor parallel + sequence parallel 相对于原来的 tensor parallel 通信量并没有增加。不仅如此,在后向代码的实现上,还把 reduce-scatter 和权重梯度的计算做了 overlap,进一步减少了通信所占用的时间。
Pipeline Parallel
Pipeline Parallel 通过将模型的不同 layer 分配到多个 GPU 中,并将它们组成一个流水线的方式进行前向和反向传播。相对于 Naive Pipeline Parallelism,GPipe 将输入的 mini-batch 切分成多个 micro-batches,当第一个卡计算完一个 micro-batch 的数据之后,传给第二张卡,然后立马去计算下一个 micro-batch 的数据。
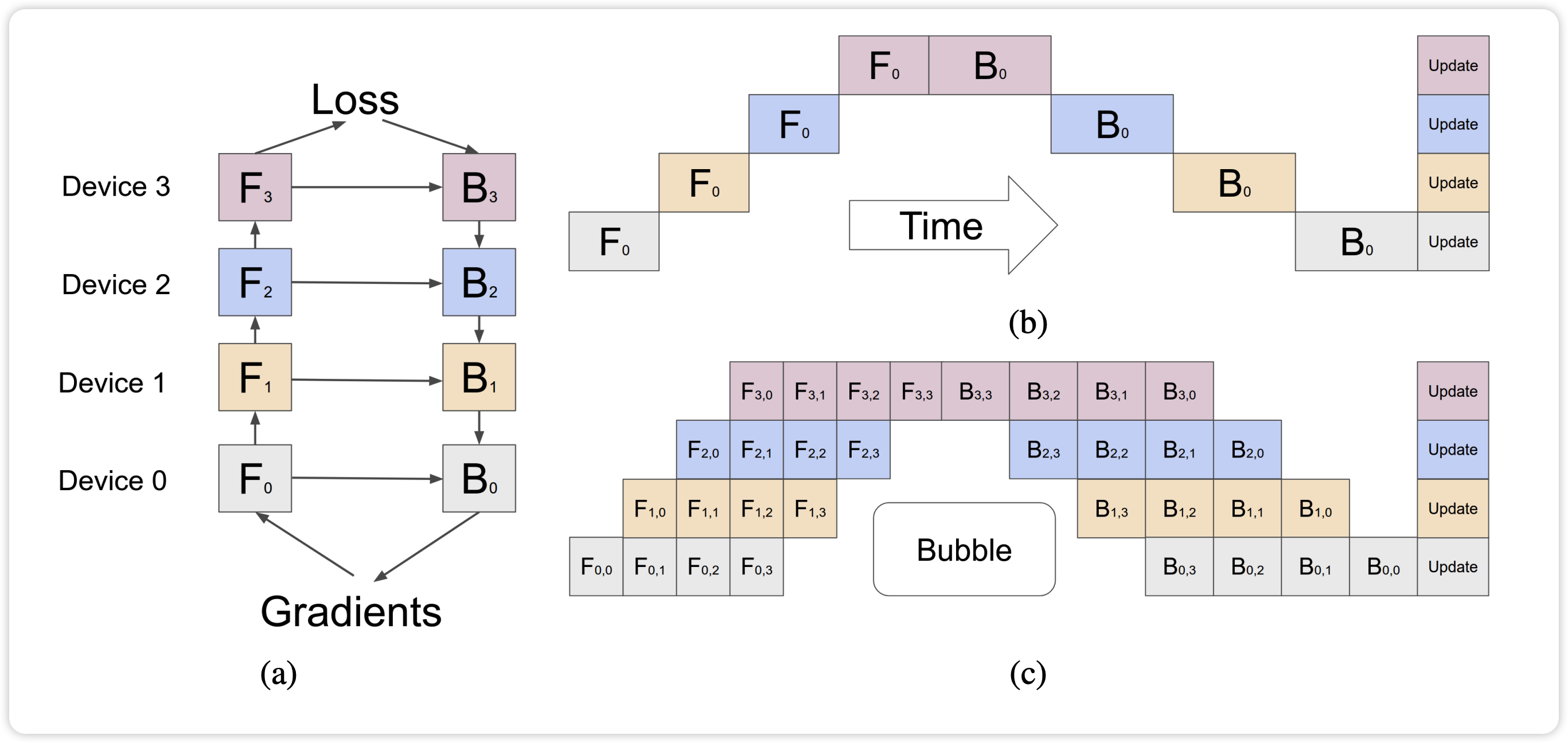
下面我们计算下流水线并行中不同 schedule 策略下 Bubble 的比例,计算中参数定义如下:
- 每个 micro-batch 中,forward 需要时间为 $t_f$ ,backward 需要时间为 $t_b$。
- 下面几张图来自 Megatron 论文11,我们假设: $t_b = 2 * t_f$
- 流水线并行中并行的 stage 为 $p$ 份,也就是一个 pp group 中有 $p$ 个 GPU
- 下图中,假设 $p = 4$,也就是有 4 个 GPU
- 假设网络共有 16 层,编号为 0~15,那么每一个 pipeline stage 划分的 layer 为
- device 1: layer(0, 3)
- device 2: layer(4, 7)
- device 3: layer(8, 11)
- device 4: layer(12, 15)
- micro-batch 数目为 $m$
- 下图中,假设 $m = 8$
对于 GPipe 流水线调度策略,先累积 $m$ 次 forward,然后执行 $m$ 次 backward。一次 mini-batch 中
- 前向和反向实际用于模型计算的时间为 $t_{ideal} = m (t_f + t_b)$
- GPU 处于空闲的 Bubble 时间为 $t_{bubble} = (p-1)(t_f + t_b)$
Bubble 比例为:
$$ BubbleRatio = \frac{t_{bubble}}{t_{ideal}} = \frac{p-1}{m} $$
可以看到,GPipe 方案中 micro-batches 数目越多,bubble 的比例越小。但是, $m$ 个 micro-batch 反向算梯度的过程,都需要之前前向保存的激活值,所以在 m 个 micro-batch 前向结束时,达到内存占用的峰值。也就是说,对于 GPipe 方案,设备内存一定时,$m$ 的数目受到限制,不然会很快 OOM。
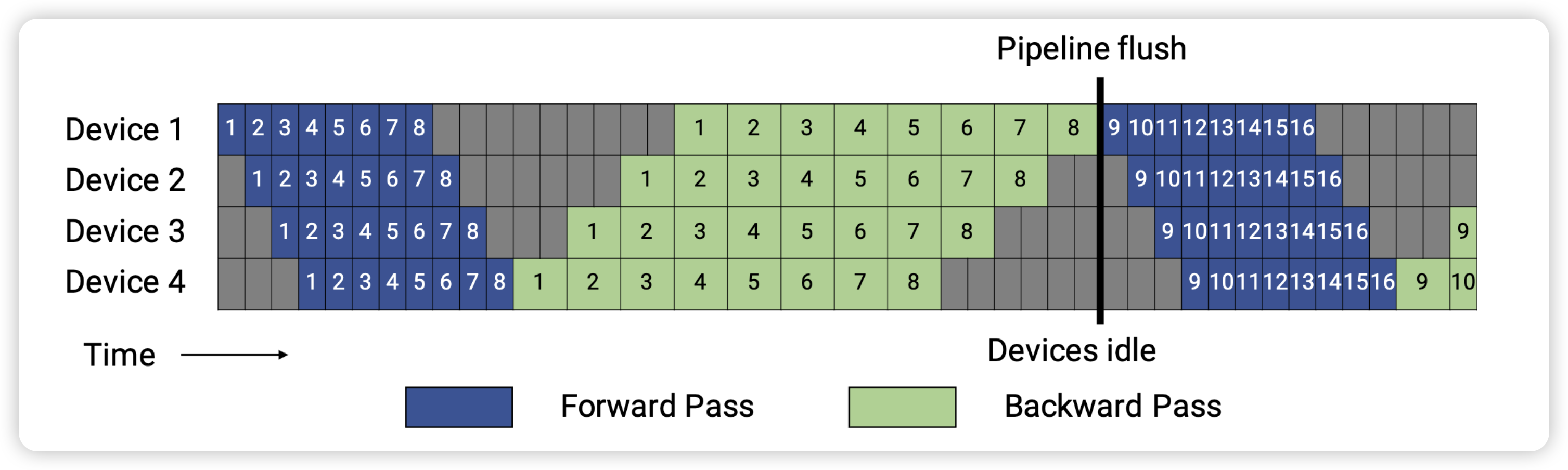
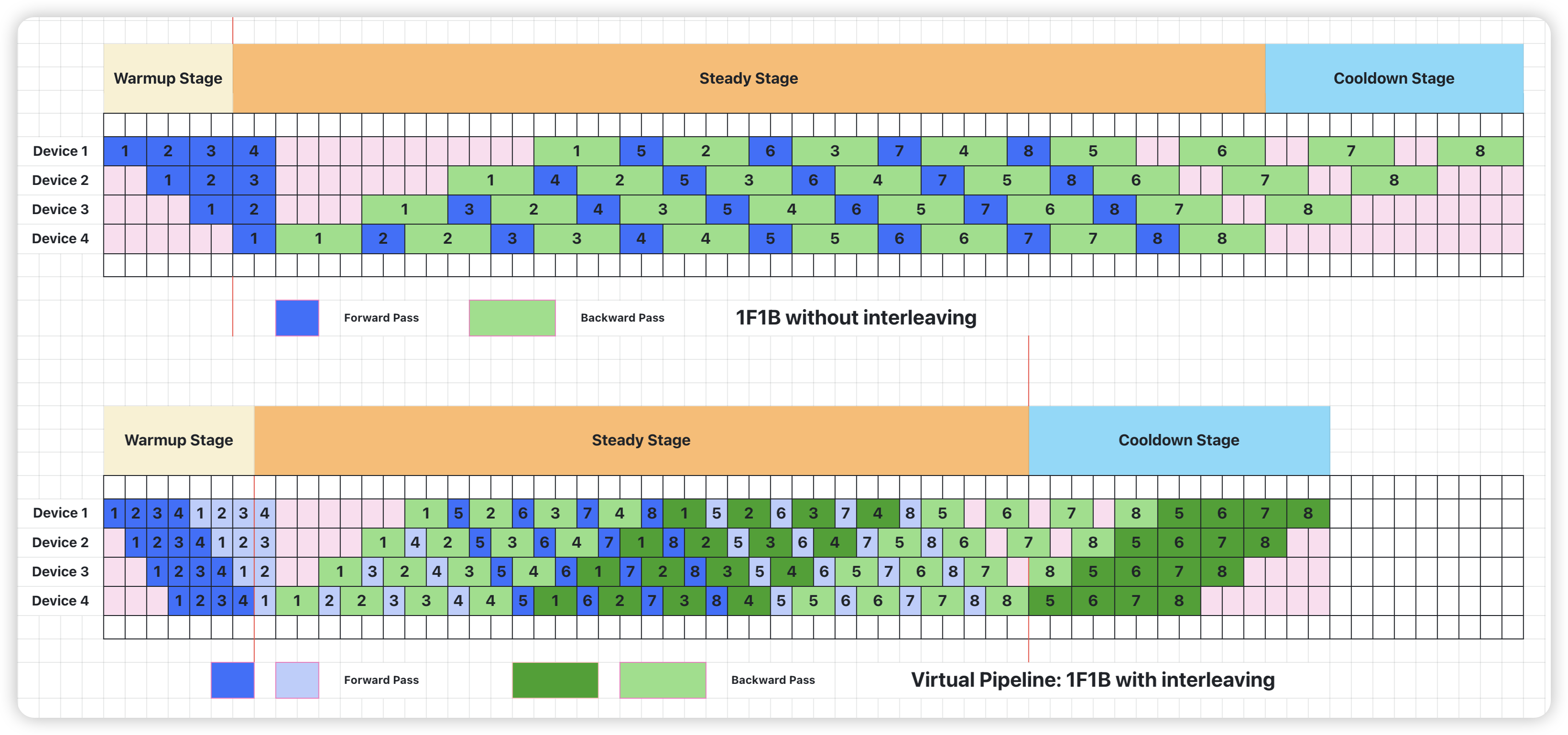
为了优化流水线并行时内存占用,PipeDream 提出 1F1B 调度策略。1F1B 通过合理安排前向和反向过程的顺序,在 step 中间的稳定阶段,形成 1 前向 1 反向的形式。Megatron 中 1F1B 的实现可以参考 forward_backward_pipelining_without_interleaving 函数12,具体可以分为 3 个阶段:
- Warmup Stage: 只做 forward
- Steady Stage: 每个 worker 接收来自上一个 worker 的输出,在本 worker 执行 forward 后立即执行 backward
- Cooldown Stage:只做 backward
可以看到,相对于 GPipe 方案,1F1B 并没有减少 Bubble 的时间,但是 1F1B 通过及时安排反向过程,将前向激活值释放掉,避免积累太多激活值占用内存,提高了模型并行的能力。
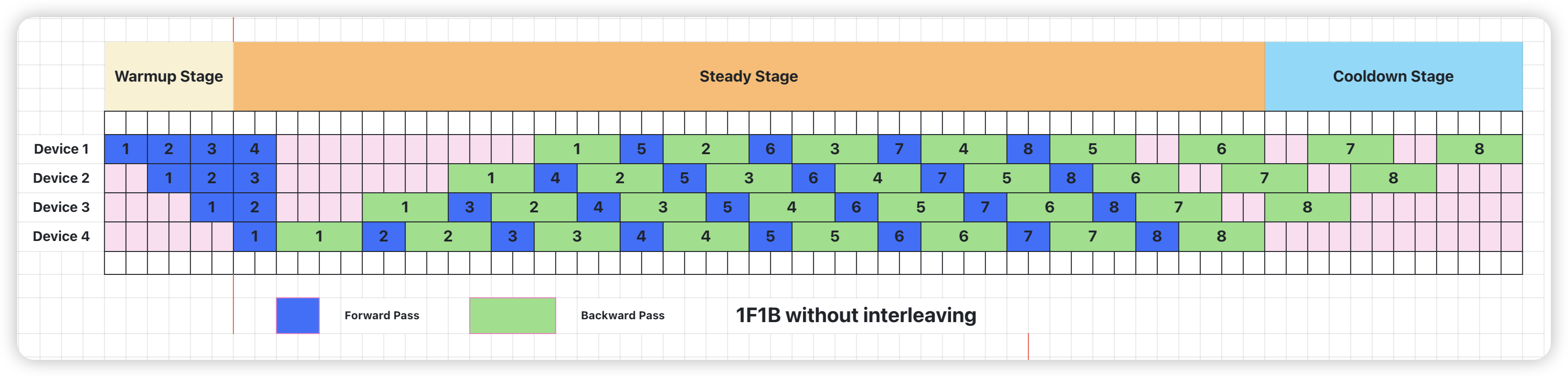
Pipeline Parallel: 1F1B without interleaving
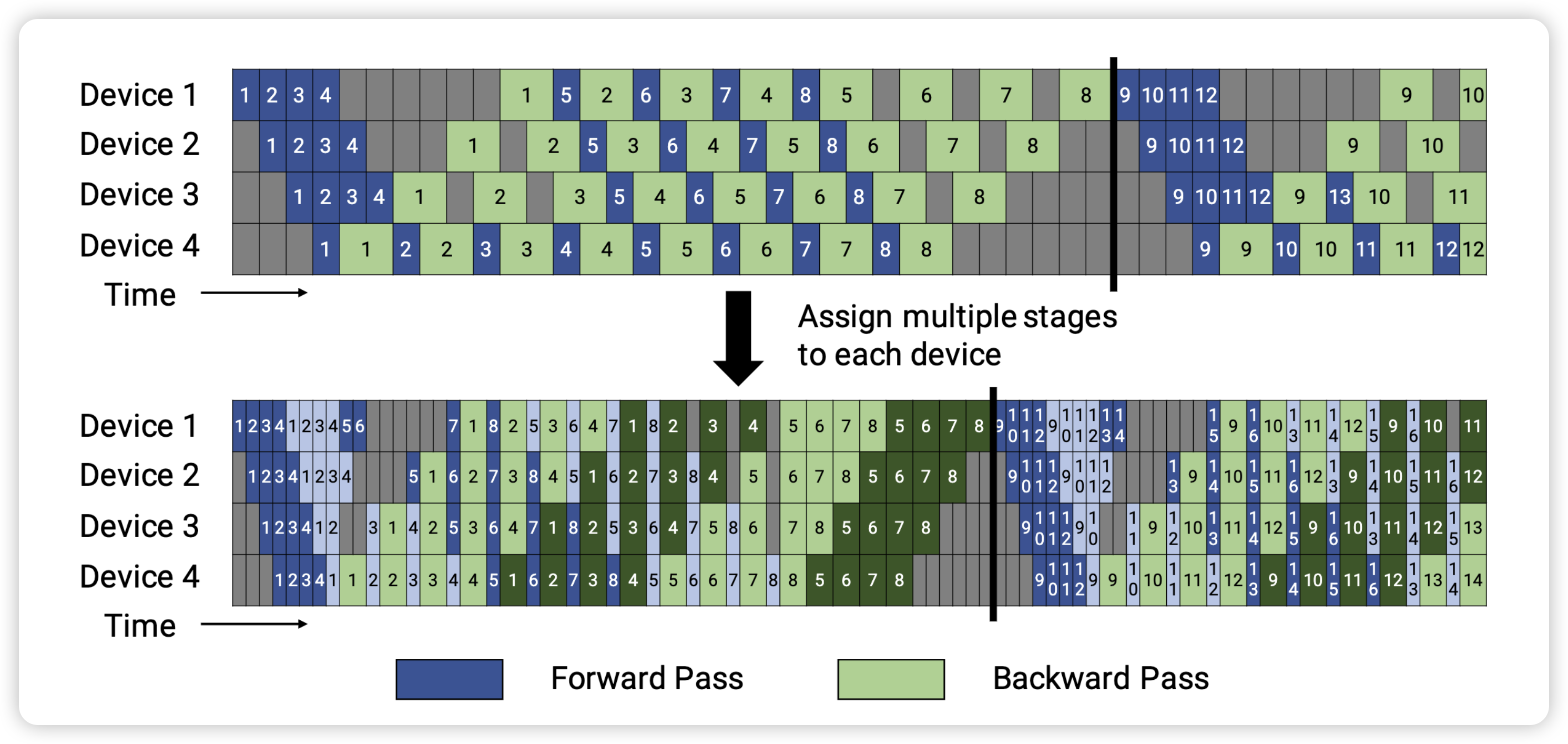
virtual pipeline 是 Megatron-2 这篇论文中最主要的一个创新点。它通过在 device 数量不变的情况下,分出更多的 virtual pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时。也就是说,在原来 pipeline stage 的基础上,每个 pipeline stage 被分成 $v$ 个 virtual pipeline stage。对比上面的配置,则对应 pipeline stage 为
- 假设网络共有 16 层,编号为 0~15,那么每一个 pipeline stage 划分的 layer 为
- Device 1: layer (0, 1) + layer (8, 9),有两个 virtual pipeline stage
- Device 2: layer (2, 3) + layer (10, 11),有两个 virtual pipeline stage
- Device 3: layer (4, 5) + layer (12, 13),有两个 virtual pipeline stage
- Device 4: layer (6, 7) + layer (14, 15),有两个 virtual pipeline stage
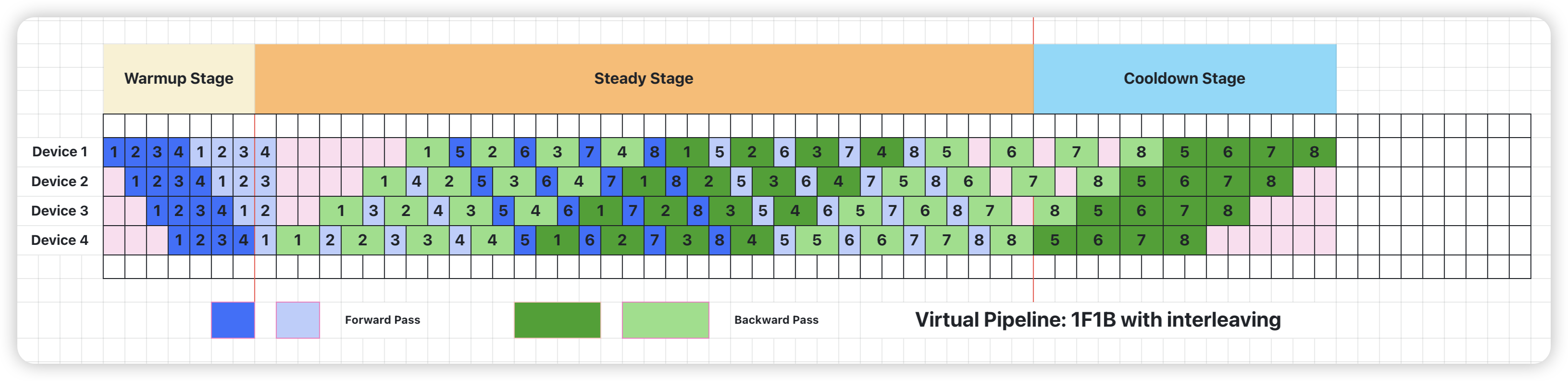
Megatron 的这种 virtual pipeline 也称作 1F1B-interleaving,具体实现可以参考forward_backward_pipelining_with_interleaving 函数 13。按照这种方式,Device 之间的点对点通信次数(量)直接翻了 virtual_pipeline_stage 倍,但空泡比率降低了,若定义每个 Device 上有 $v$ 个 virtual stages,或者论文中也叫做 model_chunks,这个例子中 $v=2$
- 前向和反向每个 virtual pipeline 的时间分别是 $t_f/v$ 和 $t_b/v$
- 前向和反向实际用于模型计算的时间为 $t_{ideal} = m (t_f + t_b)$
- GPU 处于空闲的 Bubble 时间为 $t_{pb}^{int.} = \frac{(p-1)(t_f + t_b)}{v}$
Bubble 比例为:
$$ BubbleRatio = \frac{t_{pb}^{int.}}{t_{ideal}} = \frac{1}{v} * \frac{p-1}{m} $$
现在,空泡比率和 $v$ 也成反比了。
备注:这里我画的图和 Megatron 论文中的图在 Forward 处有些微差别,但本质上是一样的
以 Megatron 为例,175B 的 GPT-3 训练,$p=16$ 个 stage,$m = 1536$ 个 micro-batch,气泡损耗占比很低。
|
|
Expert Parallel
在 当计算撞上内存墙:Attention!注意力机制及其优化算法浅析 中我们看到,随着模型和数据规模的增大,每个训练样本都需要经过模型的全部计算,导致了训练成本的平方级增长。为了解决这个问题,Mixture of Experts(MoE)通过选择性地激活模型中的一部分参数来处理不同的输入数据,从而实现超大规模稀疏模型的训练。
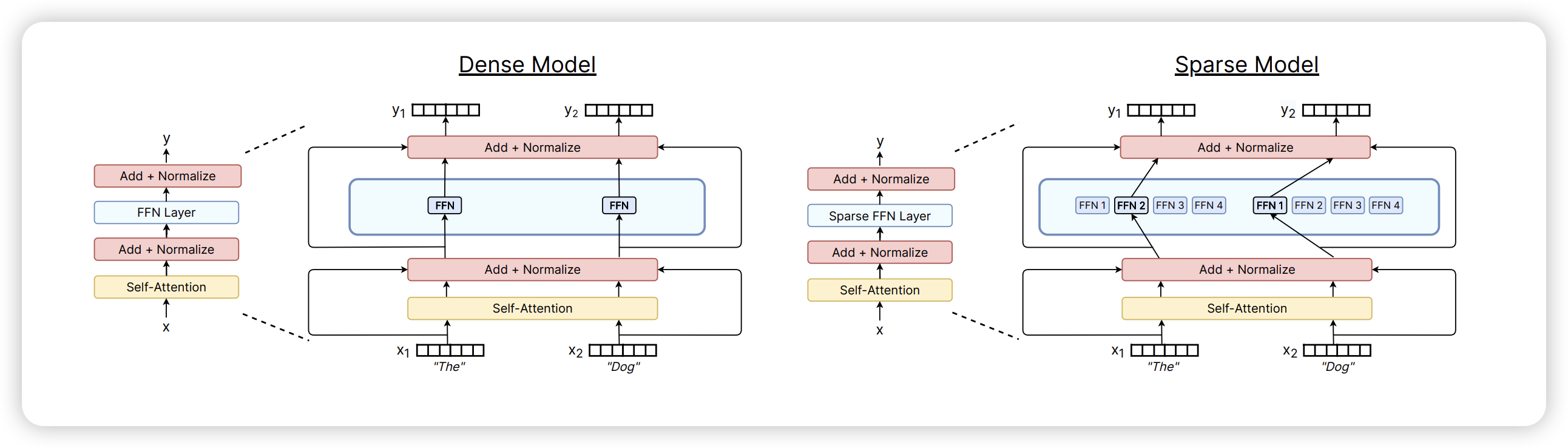
HuggingFace 的 Mixture of Experts Explained 这篇文章14 对于 MoE 有一个全面的介绍,十分推荐阅读,作为引用,这里简单介绍下 MoE 训练对于通信带来的挑战。
作为基于 Transformer 的 MoE 模型,主要由以下两部分组成:
- 稀疏 MoE 层:它将 FFN 拆成多个子层,每一个子层被称为
Expert。一般来说,这些 Expert 都是 FFN,但是也可以是更复杂的网络,甚至是 MoE 本身 - Router:也被称为 Gating Network,这部分用于决定将哪些 token 被发送到哪些 Expert
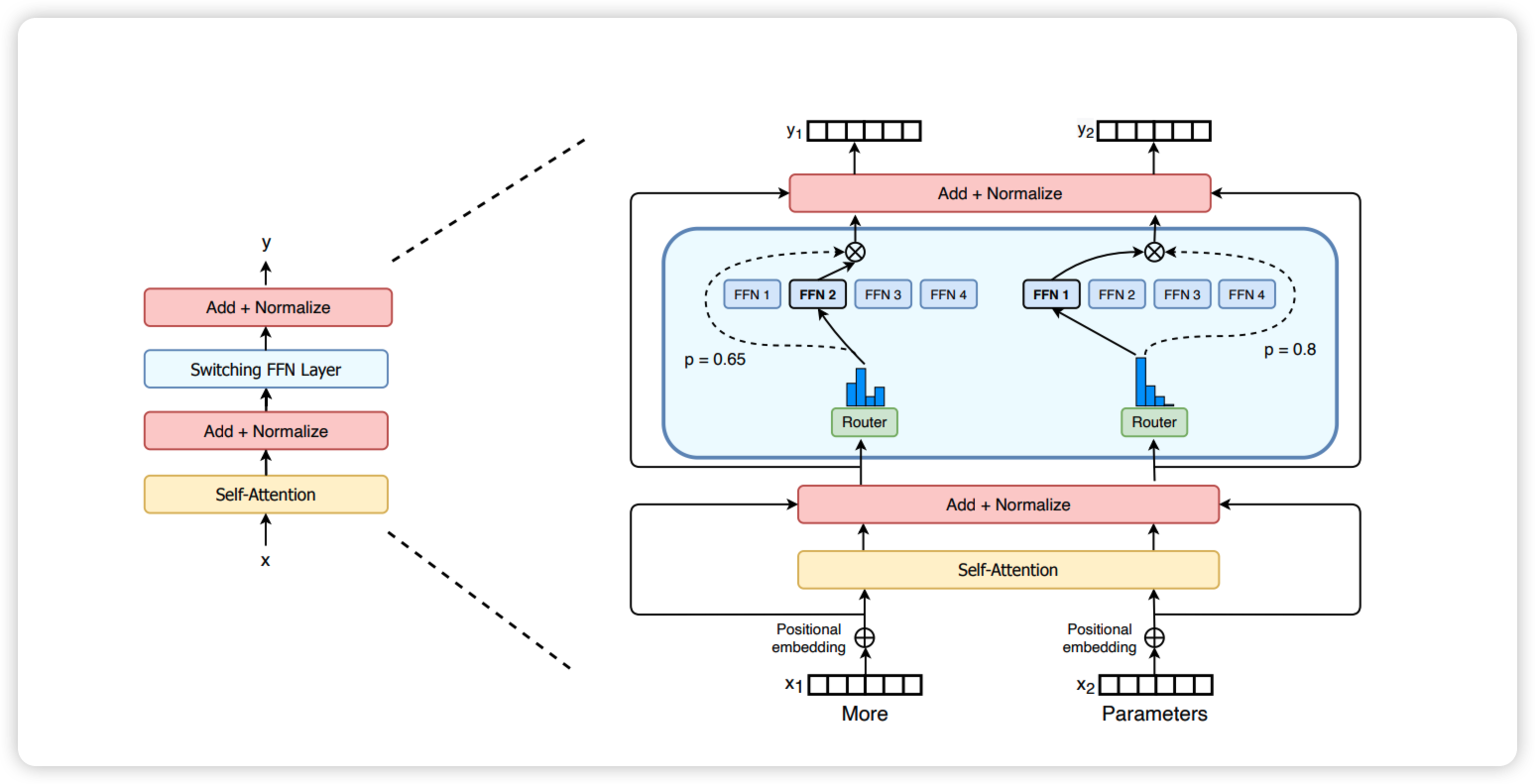
Switch Transformer
MoE 的整个计算过程如下所示:
Routing: Token 通过和 Router Weights 矩阵相乘得到一个路由分数矩阵,然后 Softmax 来决定该 Token 需要发送给哪些 ExpertPermutation:Router 产生一个 Expert Indices 后,GPU 会根据这个决策矩阵构建本地的置换 Token 位置的后的临时矩阵,然后通过 All-to-All 通信发送给不同的 Experts 所在的 GPU 进行运算Computation:Permutation 完成重排序的 Token 数据输入到每个 Experts 的 MLP 中进行计算Un-Permutation:Permutation 的逆运算,把 Token 从专家返回给原来的节点,然后继续向下游处理。
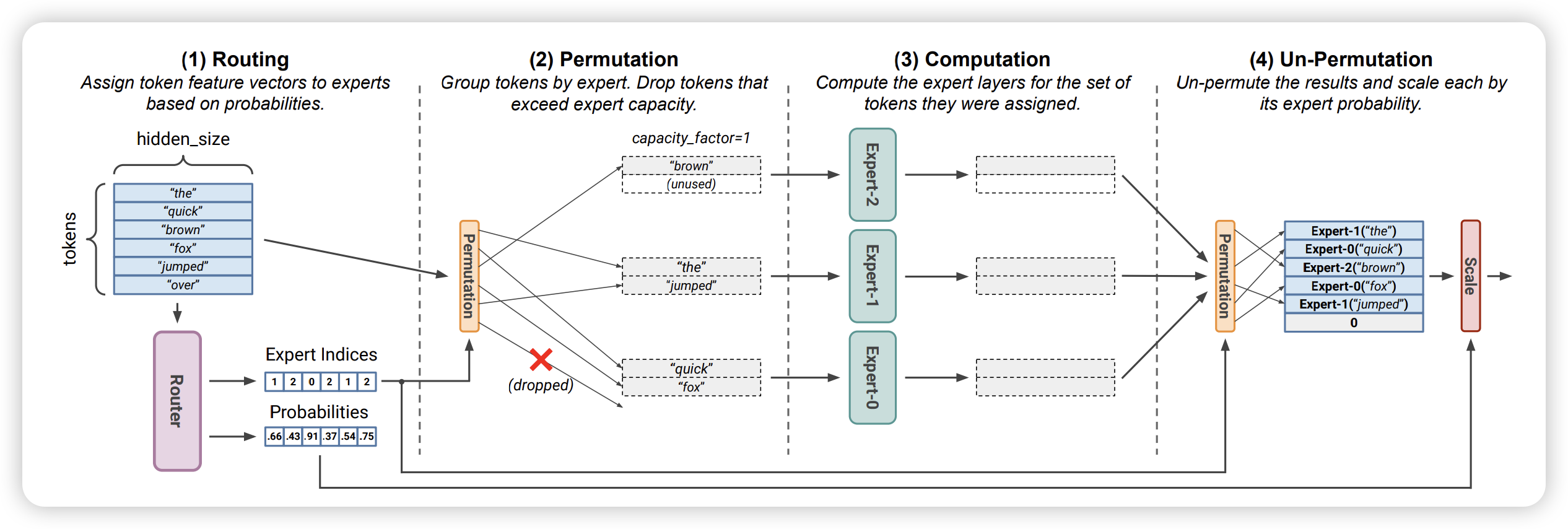
对应于伪代码如下所示:

这即展示了 MoE 训练时专家并行 Expert Parallel 的典型场景。专家并行的思路是将不同的专家分配到不同的 GPU 上,这有助于减少内存消耗并提高训练效率。计算前需要根据路有规则将 Token 通过 All-to-All 通信发送给不同的 Experts 所在的 GPU 进行运算。
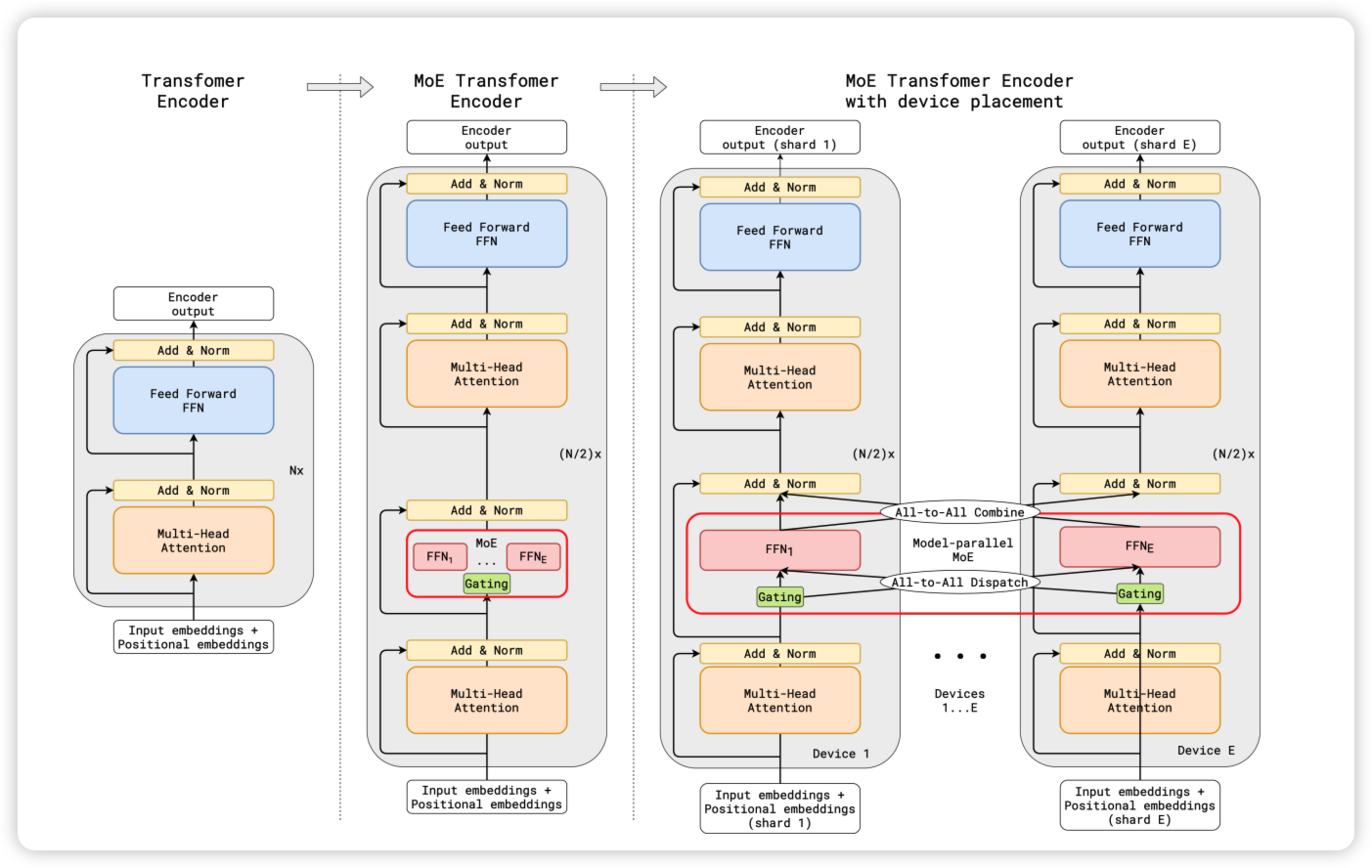
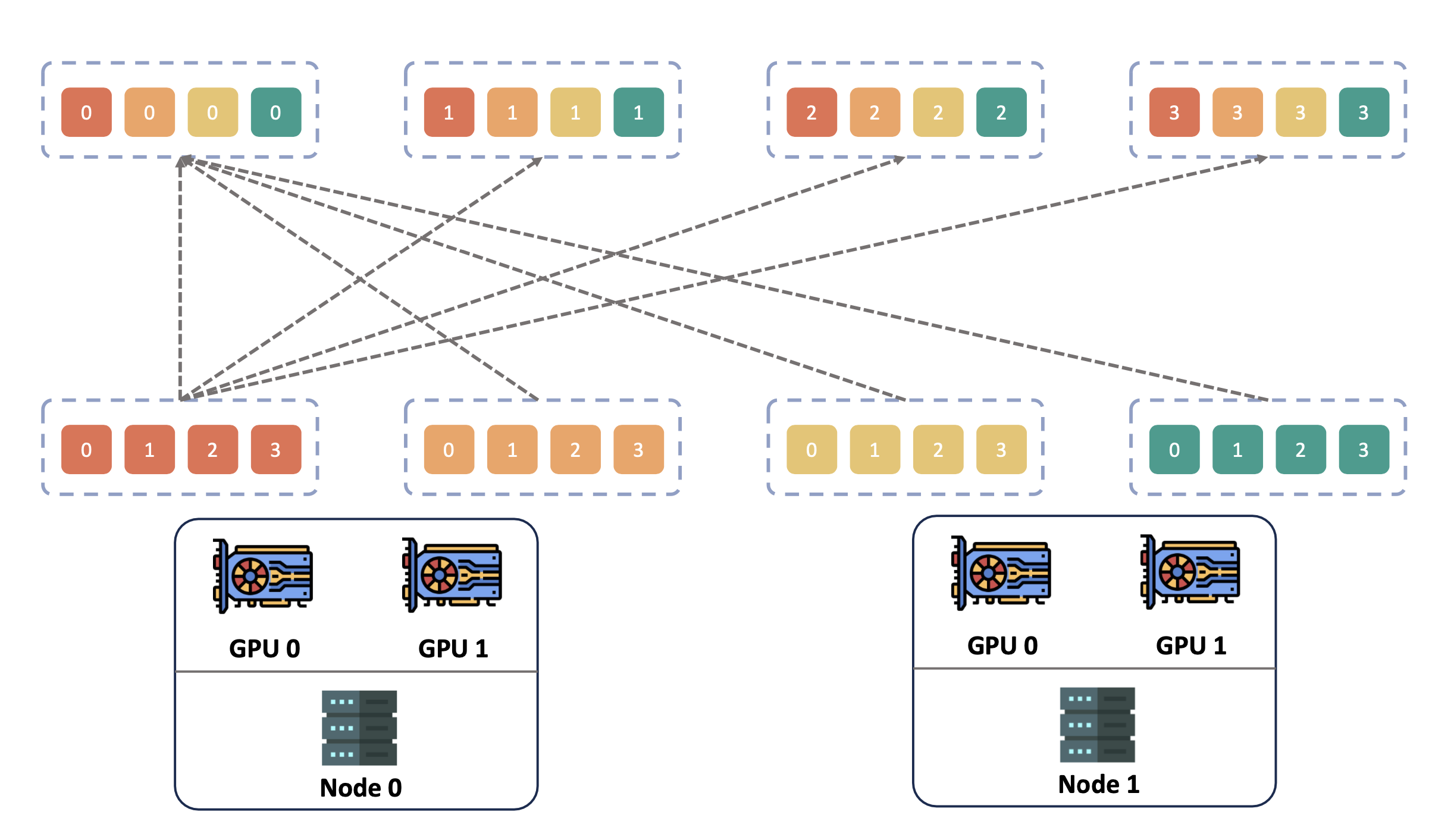
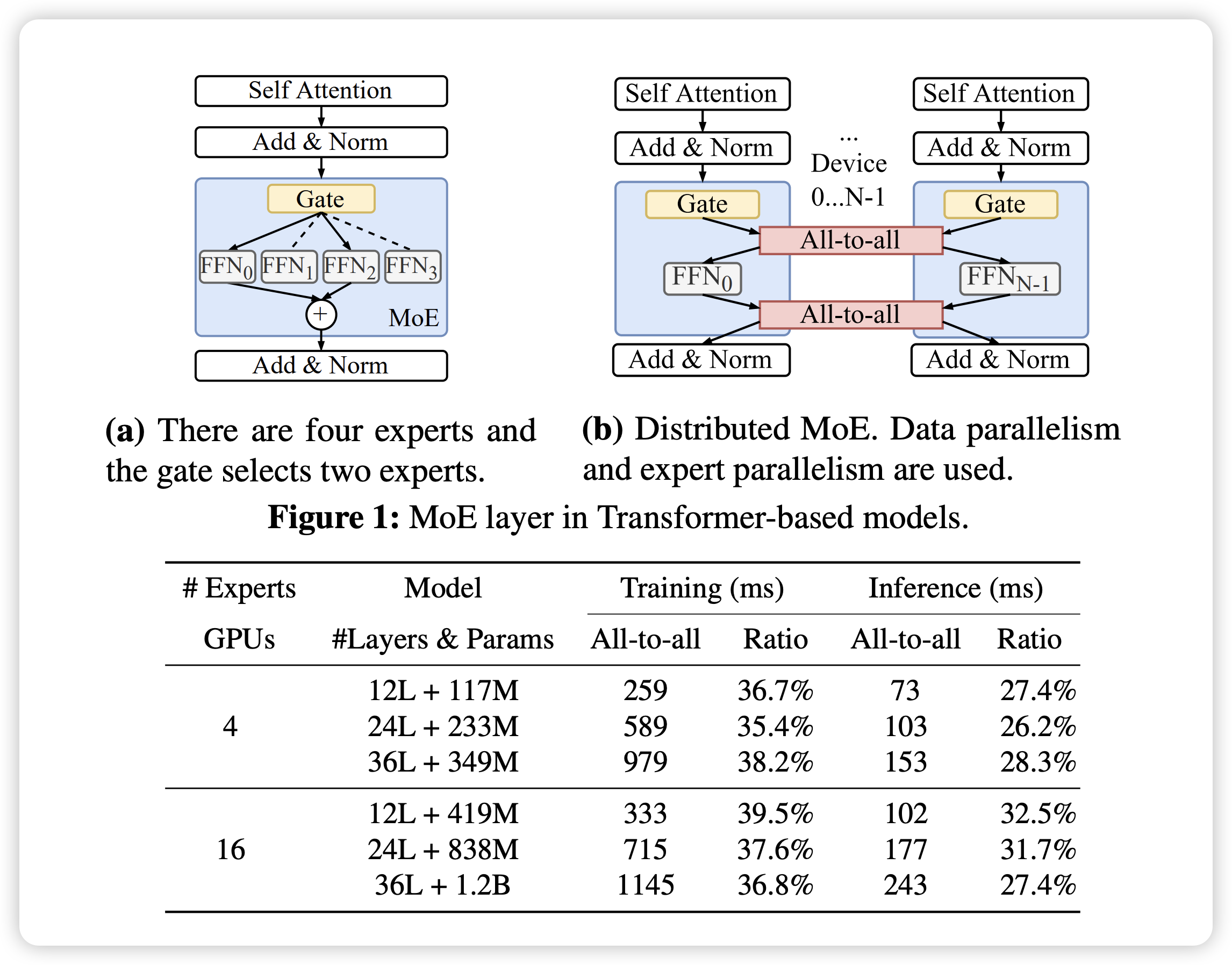
All-to-All 原语如下所示,这部分通信的规模和频率呈指数级增长,导致通信时间增加,从而降低了整体训练效率。业界近期针对 All-to-All 的各种优化策略,都是极致利用网络提供的大带宽来缩短通信耗时,从而提升 MoE 模型的训练速度15161718。
Hybrid Parallel
前面我们已经回顾了目前常见的几种并行策略,如下所示,下面几张图片来自 NeMo19:




首先是 Tensor Parallel 结合 Pipeline Parallel,先按照层竖着切,将模型切成几个 Pipeline Stage,然后横着切,对每一个 Pipeline Stage,切分成多个 Tensor Partition。
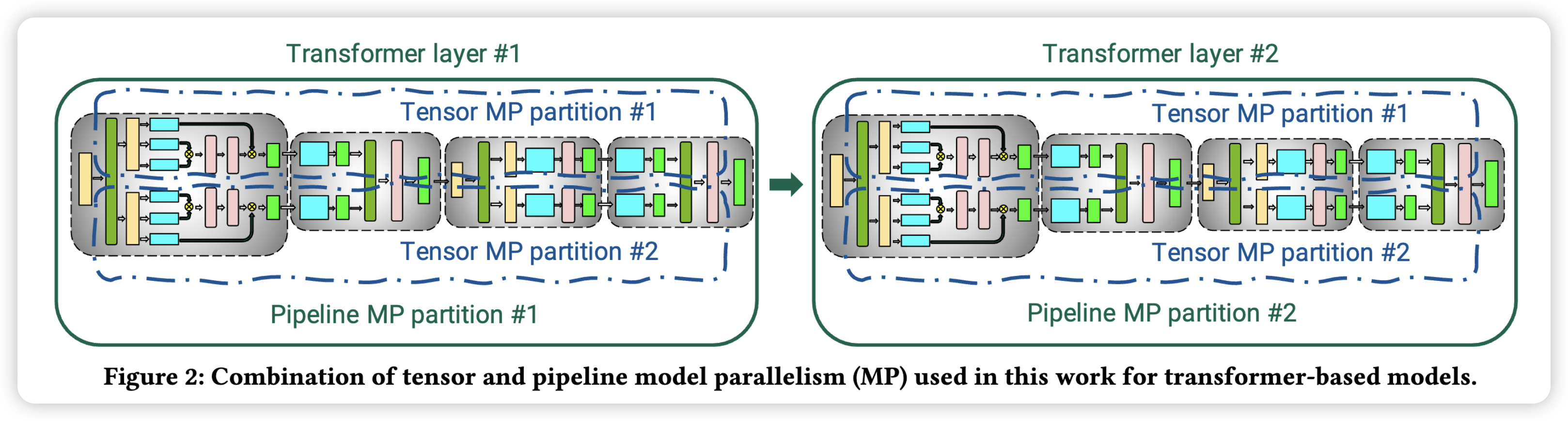
如前所述,TP 将一个多层神经网络按照横向切分的方式拆成多个子模型,通常需要在神经网络的每一层进行全局参数同步,通信量最大,一般同一个 TP Group 的 worker 分布在同一个节点,通过机内 NVLink 通信。常见 GPU 服务器上有 8 个 GPU,因此 tp 一般小于等于 8。
而 PP 则在层之间通过 send/recv 点对点通信,通信量相对 TP 较小。但是,这个时候受限制的是 GPU 的内存,当流水线并行层级增多时,内存上需要保存的前向过程中的激活越多,因此 PP 的流水线层级也不能过深。
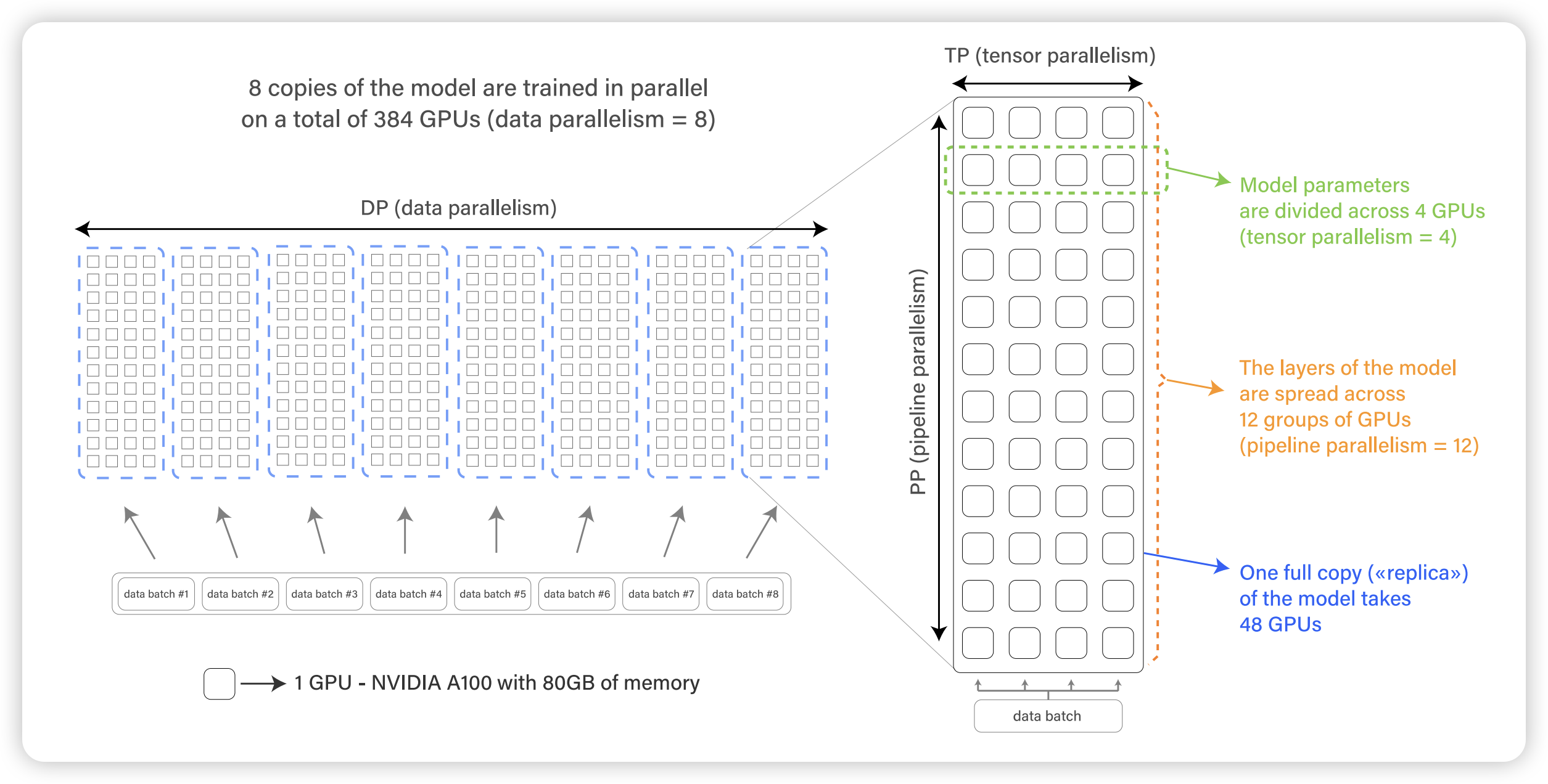
为了进一步 Scale,我们会继续用上数据并行,因为经过 TP 和 PP 的切分,这个时候每个 Model Shard 已经可以放在一个 GPU 上。在每个同样的 Model Shard(同一个 TP rank,同一个 PP rank 的 model shard)之间继续使用 DP,如上图所示。
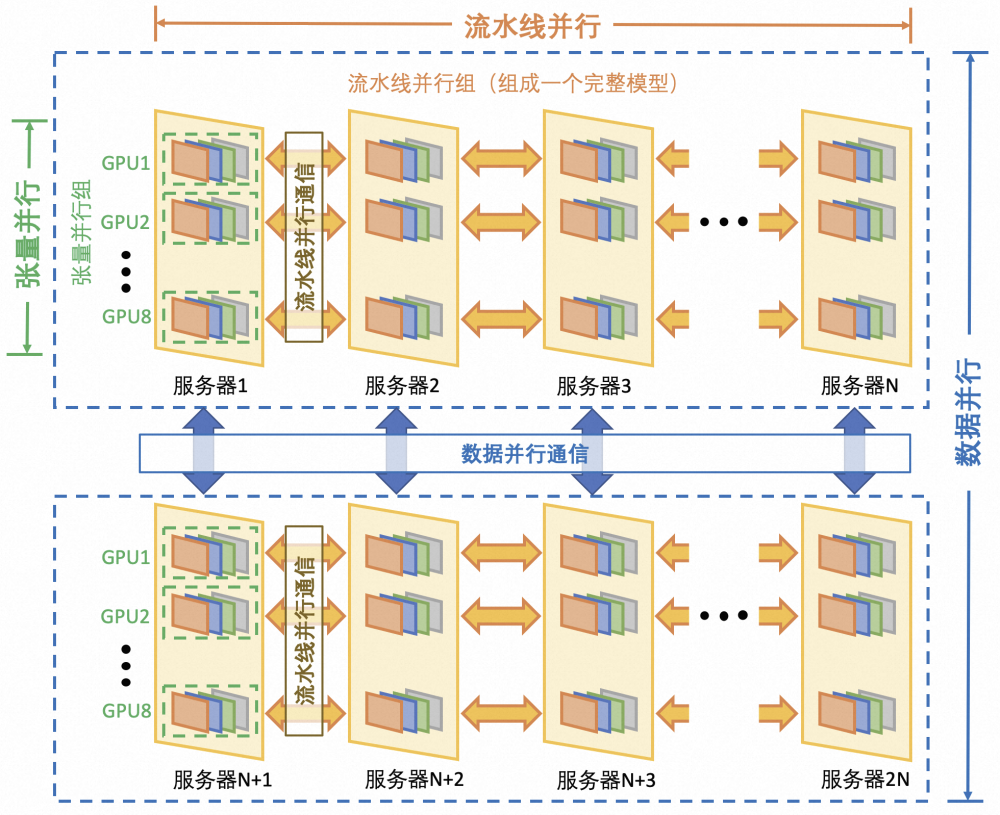
对应到集群中实际训练时的拓扑,首先是每一个模型按照流水线并行切成多个 pipeline stage,每个 pipeline stage 继续按照张量并行,同一个 tp group 一般分布在同一个节点。对于 DP,则实际上是每个节点上的同号 GPU 进行通信,如下所示。
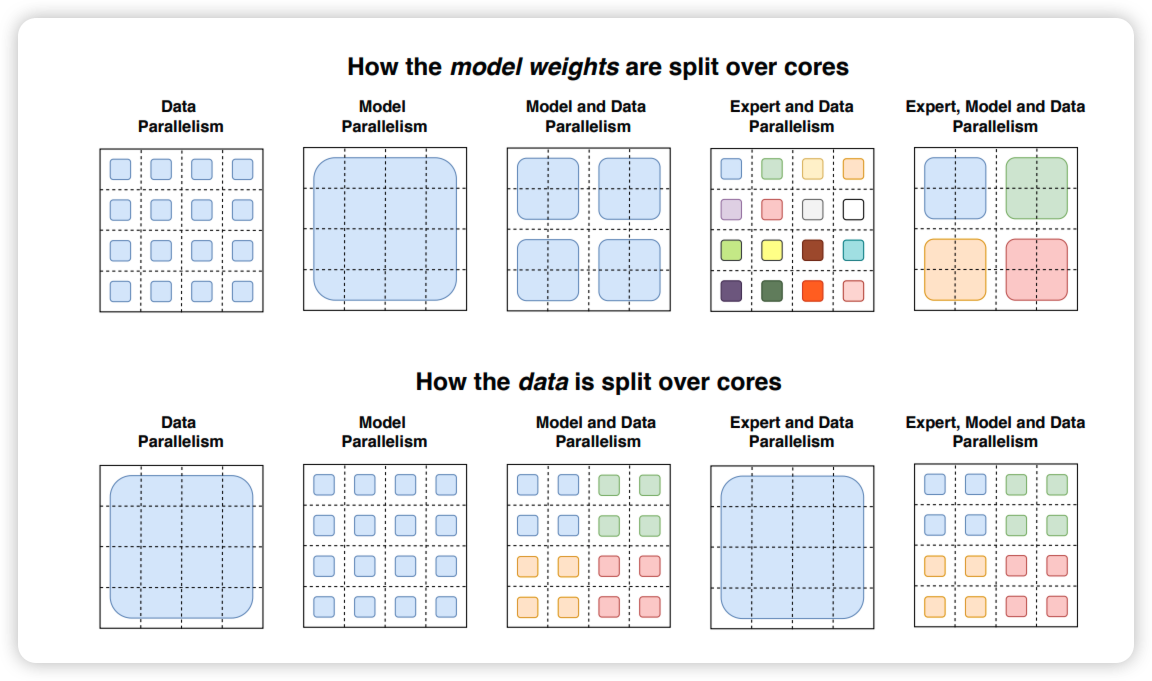
关于模型并行和数据并行的切分方式如下所示,这里并不涉及专家并行的混合并行,以后有机会再进一步讨论。
总结一下 3D 并行对于网络的需求:
| 并行策略 | 通信模式 | 每轮迭代数据量 |
|---|---|---|
| 数据并行 DP | AllReduce 同步梯度,可以被拆成 AllGather/ReduceScatter | 与模型规模相关,单卡可以达到 10 GB+,每个 step 一次通信 |
| 张量并行 TP | AllReduce 同步矩阵乘的结果,可以被拆成 AllGather/ReduceScatter | 与 batch size 有关,矩阵可以达到 GB 级别,一个 step 几十次通信c |
| 流水线并行 PP | 点对点通信,正向传递激活,反向传递梯度 | 与层间交互相关,一般在 MB 级别,一个 step 几十次通信 |
机内与机间通信的物理设施
上一节我们主要介绍了几种常见的并行训练模式,并分析了各种训练模式对于通信的需求。本小节将自上而下地梳理整个集群互联的基础设施,理解集群拓扑,进而更好地理解整个集群训练时通信的典型场景。
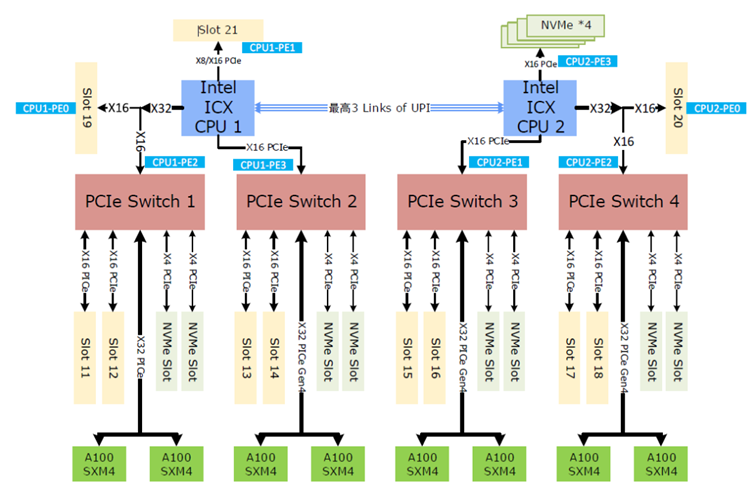
首先看单机内的通信,下图是典型的 A100 服务器互联拓扑图:
- 节点上 2 个 CPU NUMA Socket,之间通过 UPI 20互联
- 每个 CPU Socket 作为 PCIe Root Complex 连接 PCIe Switch 进一步互联外部设备,包括 A100 GPU、高速网卡和 NVMe 存储等
可以看到,尽管 NVIDIA GPU 已经占据了整个服务器上绝大部分的价值,也依然遵循着 Intel 定义的以 CPU 为中心的互联体系,作为一个 PCIe 设备存在于节点之上。
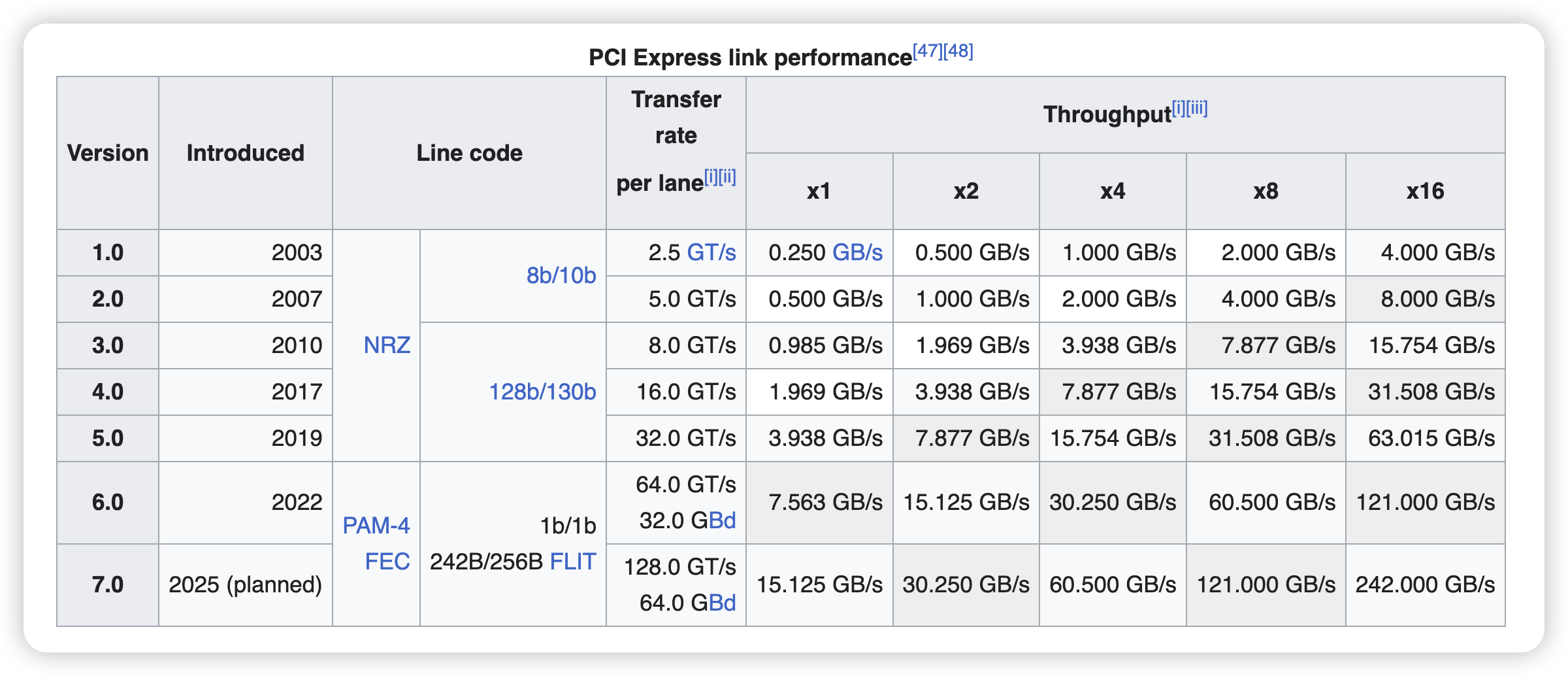
然而,Intel 主导的 PCIe 一直限制着 I/O 带宽的升级。以最新的 PCIe Gen 5 x16 为例,双向带宽也才 128GB/s,已经远远落后于 NVLink4 的 900GB/s。
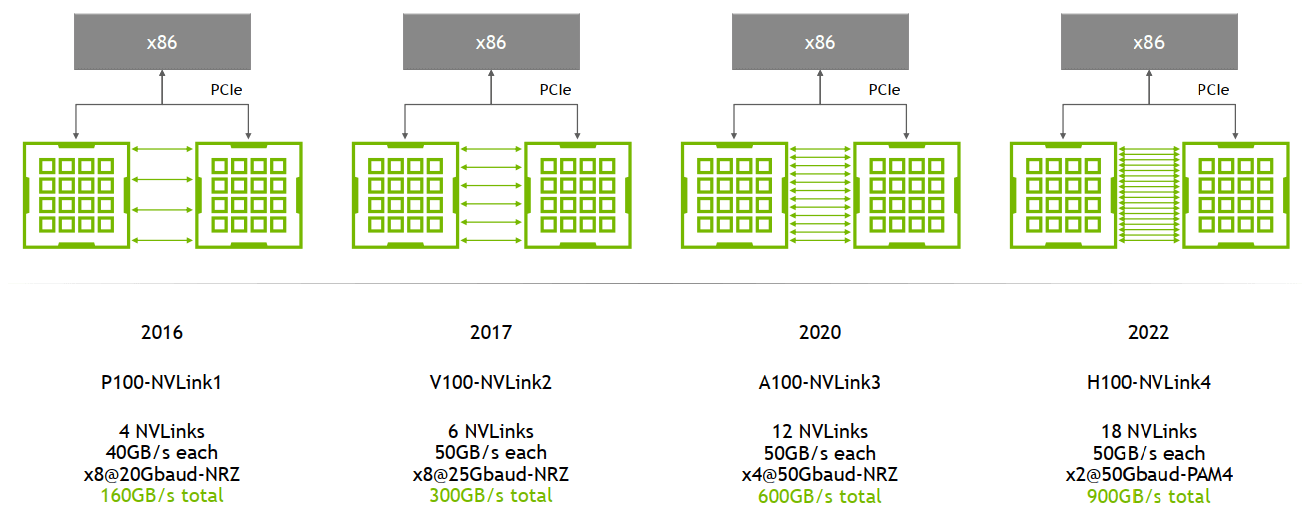
以 H100 和 H800 为例:
- 每个 NVLink4 有 2 lanes,每个 lane 运行在 100Gbps-per-lane ( x2@50Gbaud-PAM4 ),也就是说,每个 NVLink4 连接单向带宽可以达到 200 Gbps 也就是 25 GB/s,双向带宽可以达到 50 GB/s
- 对于 H100,有 18 条 NVLink4 links,总的双向带宽可以达到 50GB/s * 18 = 900 GB/s。作为参考 A100 有 12 NVLink3,总的双向带宽是 600 GB/s。
- 对于 H800,NVLink4 link 数被限制到 8,总的双向带宽可以达到 400 GB/s,单向 200 GB/s
- 同一个节点上的 GPU 通过 NVLink4 实现 full-mesh 互联
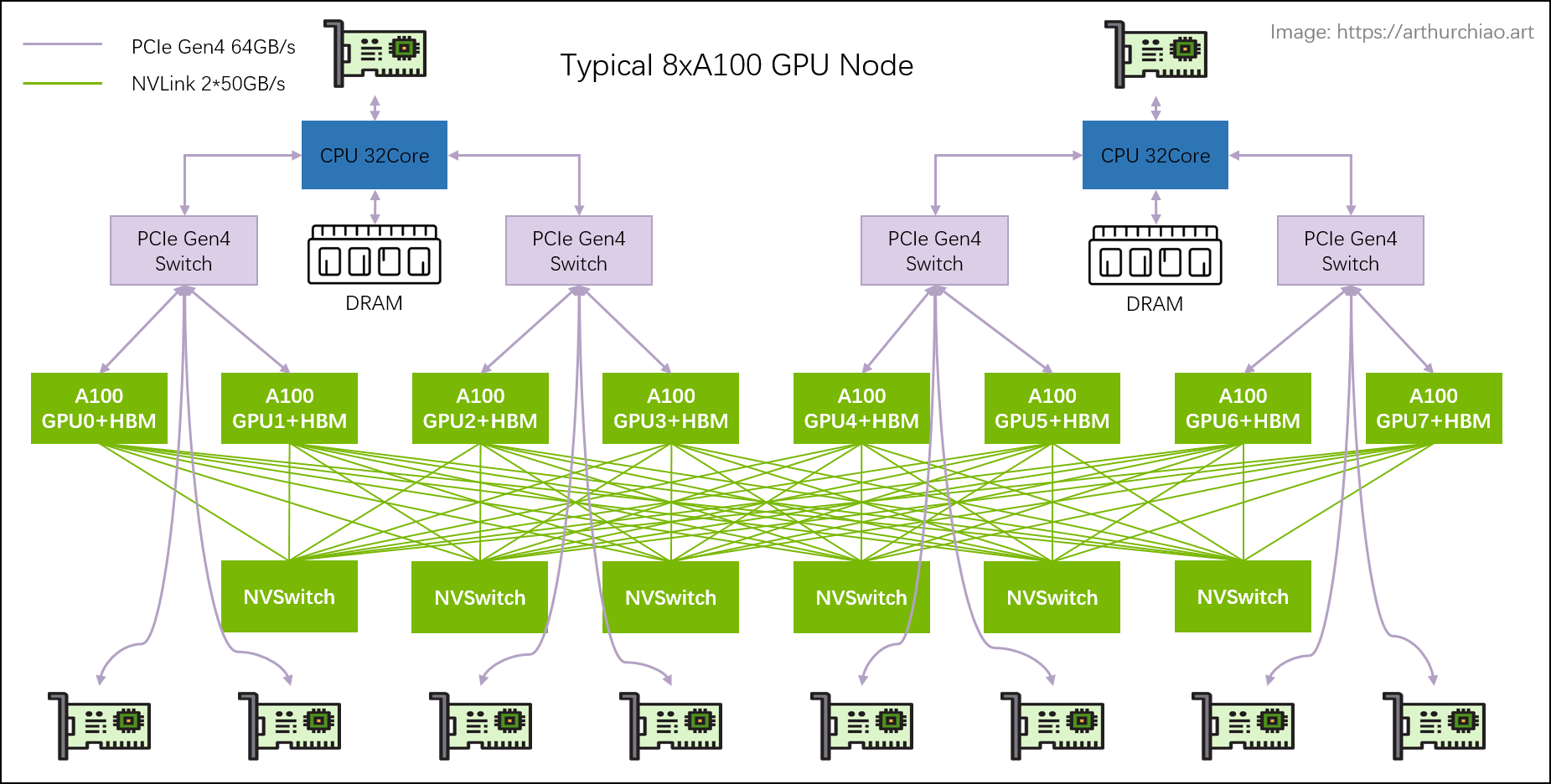
GPU 之间是如何通过 NVLink 互联起来的呢?这还依赖于节点上的 NVSwitch。NVSwitch 是 NVIDIA 的一款交换芯片,封装在 GPU module 上,并不是主机外的独立交换机,目前演进到第 3 代 NVSwitch3。
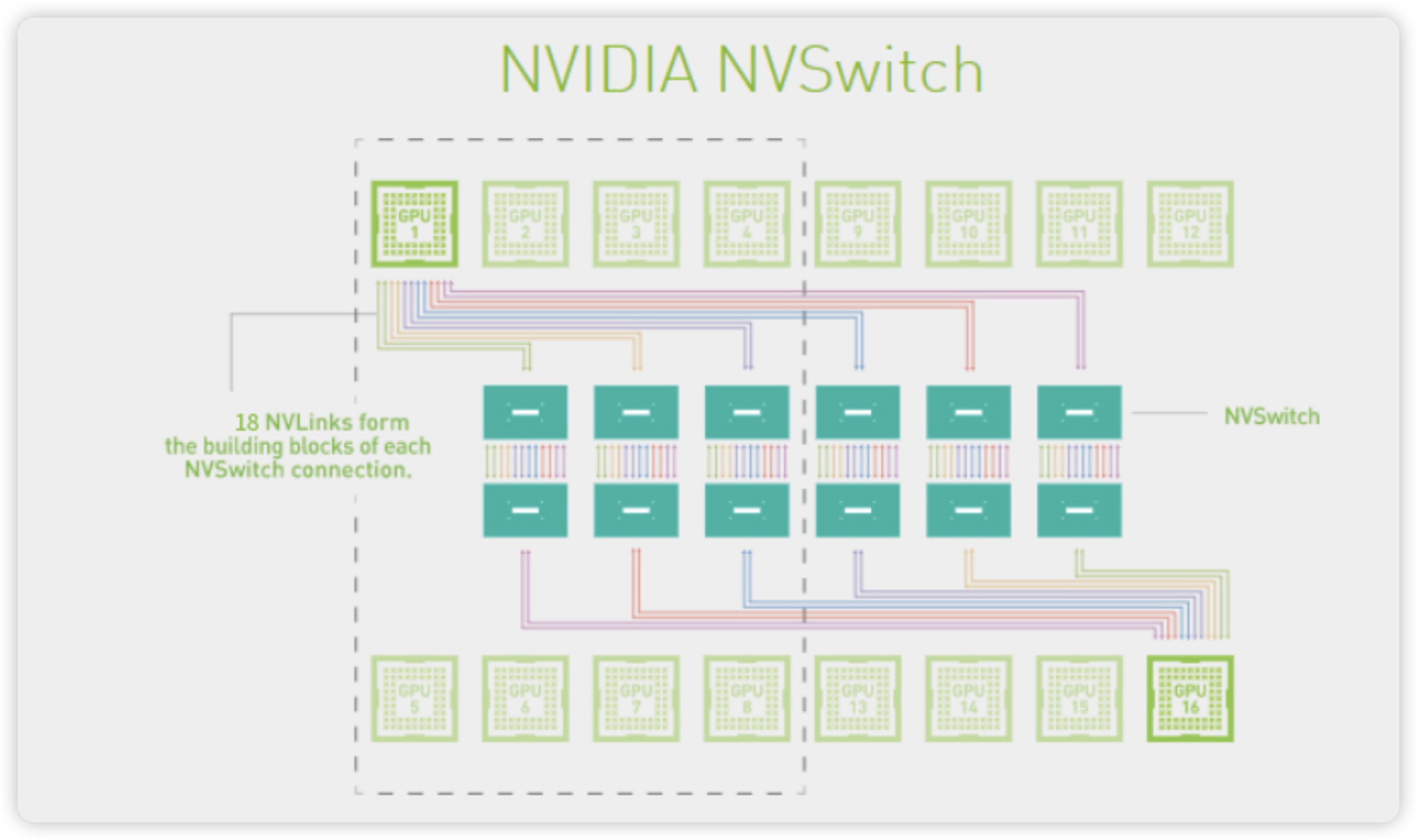
一个 NVSwitch3 提供了 64 个 NVLink interfaces,每个 NVLink4 单向带宽是 200 Gbps,因此 NVSwitch3 提供单向 64 * 200 Gbps = 12.8 Tbps (1.6 TB/s),也就是双向 3.2 TB/s

关于 NVLink 背后可能的设计思路,强烈推荐阅读夏晶老师的这篇文章21
继续在看一眼 A100 机内拓扑,除了双向 600GB/s GPU 之间互联,同一个 PCIe Switch 下,每个 GPU 还配有 1 个 200Gb/s 的网卡,单机网卡带宽为 1.6 Tb/s。
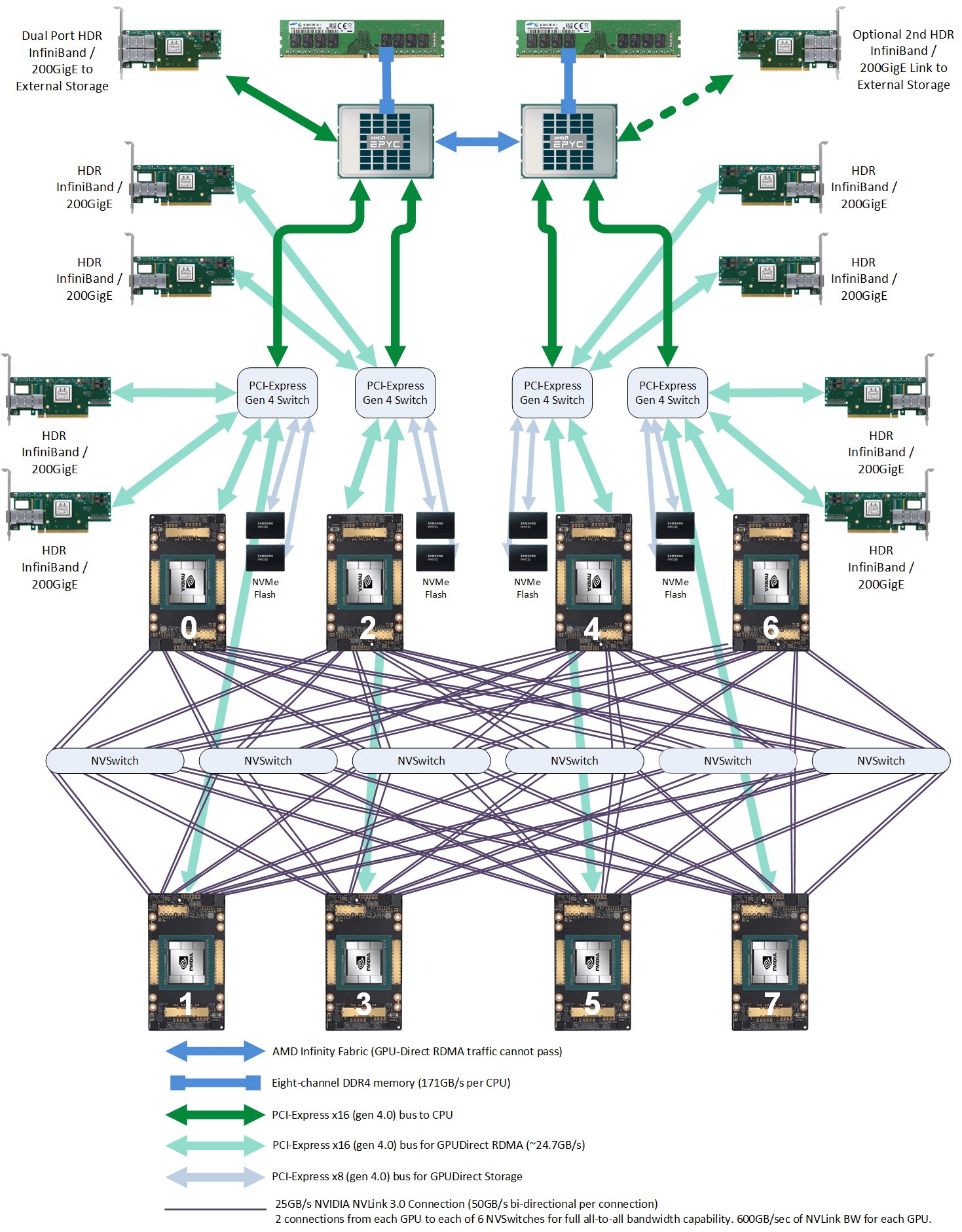
对于 H100,目前最优的网络带宽可以作为 400 Gb/s x 8,也就是单机 3.2 Tb/s 的网络带宽。
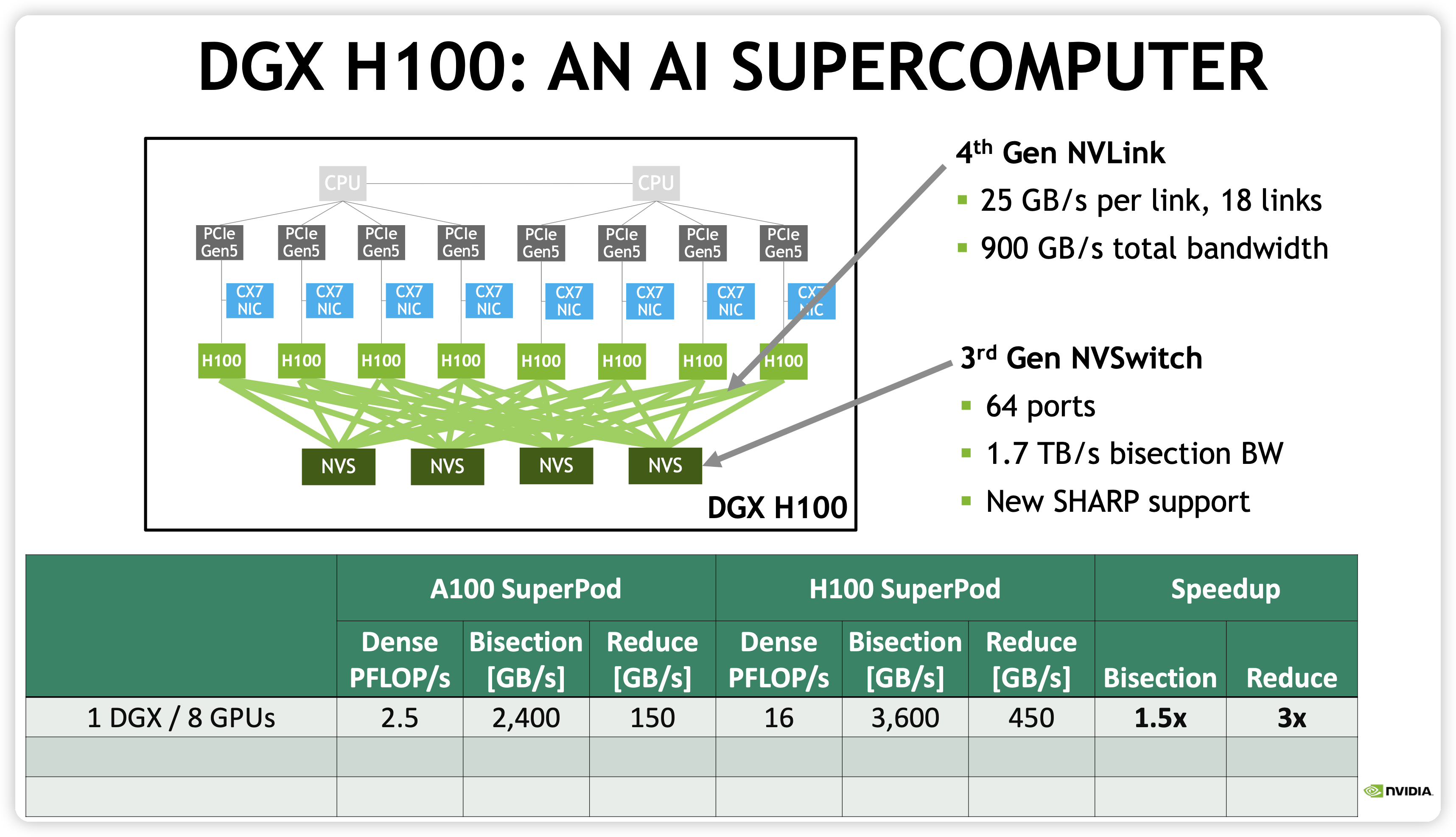
介绍完目前主流机内互联,我们继续看一看机间互联。在 DGX A100 系列,每个节点上 8 张 GPU 通过 NVLink 和 NVSwitch 互联,机间直接用 200G IB HDR 网络互联。
到了 DGX H100,NVIDIA 把机内的 NVSwitch 做到交换机上,叫做 NVLink Switch22,这几个称呼比较容易混淆,注意区分,NVSwitch 是机内的交换,NVLink Switch 已经是机间的交换机了,类似于替换了 DGX A100 的 IB HDR leaf switches。NVLink Switch 最多支持 256 个 GPU,也就是 32 机 DGX。如下所示,可以看到 32 DGX 中 256 GPU 卡 Reduce 带宽仍然可以打到 450 GB/s,和单机是完全一致的,这就是老黄说的 one mind-blowing GPU。

也就是说,收购 Mellanox 之后,老黄把原来只支持单机的 NVLink 做成了现在支持多机的 NVLink Network,如下所示。虽然现在 NVLink Network 只支持 32 机之间通信,也就是限制在 NVIDIA 的 SuperPod 之内,以后会不会进一步扩大规模进而吃到 IB 统一成一套网络呢?
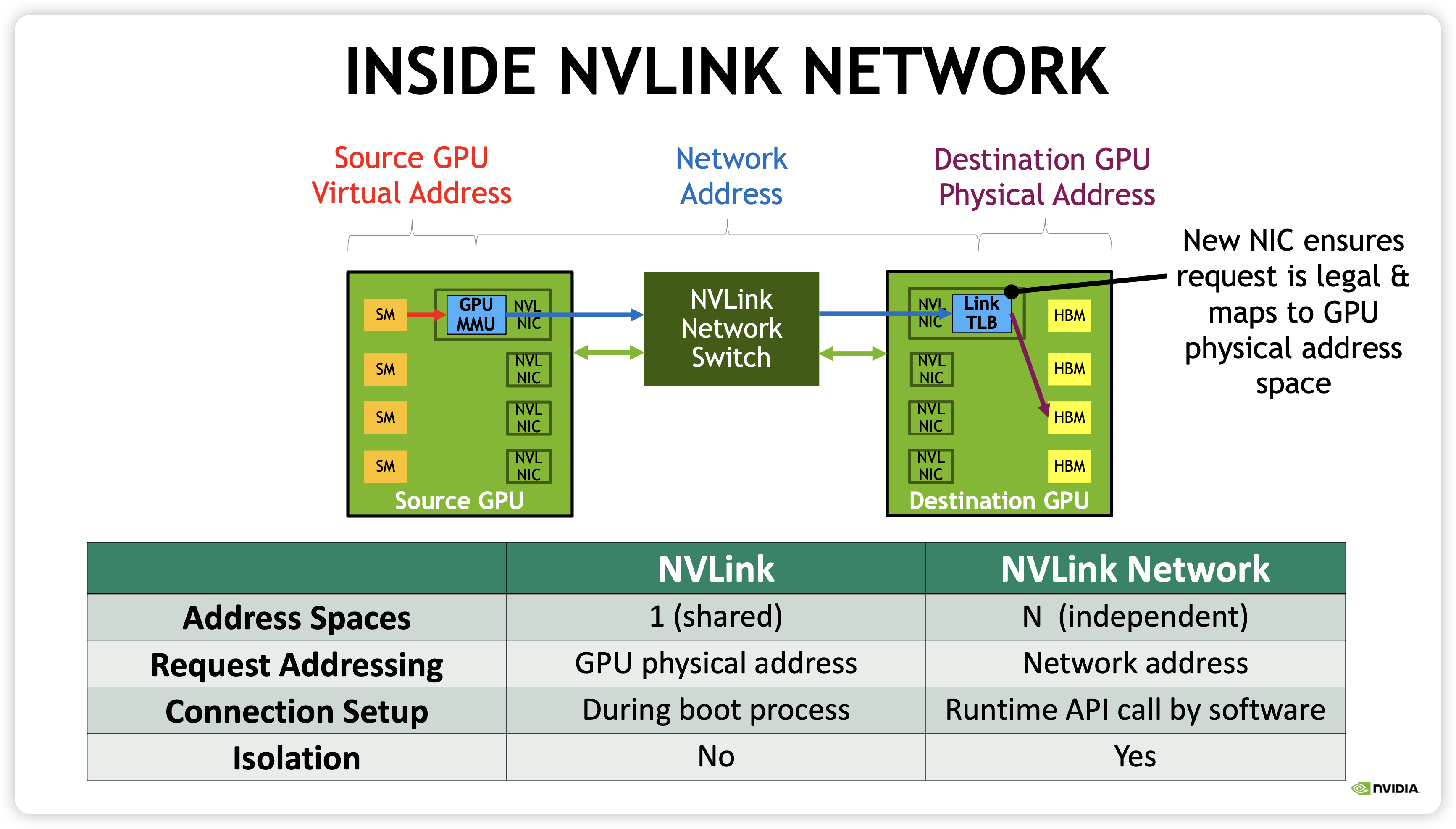
Unlike regular NVLink, where all GPUs share a common address space and requests are routed directly using GPU physical addresses, NVLink Network introduces a new network address space. It is supported by new address translation hardware in H100 to isolate all GPU address spaces from one another and from the network address space. This enables NVLink Network to scale securely to larger numbers of GPUs.
进一步扩大规模,我们来到千卡级别的集群,由 4 个 DGX H100 SuperPod 组成,通过 Infiniband NDR 网络连接。这里 NVIDIA 还专门指出了其 NVSwitch 具有的 NVLink SHARP 和 IB Switch 具有 IB SHARP 特性。SHARP 是一种 In-Network Computing,旨在将 all-reduce 这些集合通信的计算卸载到 switch 上,从而将数据通信带宽降低,实际算法带宽增加,以后有机会专门展开。

NVIDIA 的 DGX H100 互联系统,以其私有的 NVLink Network 协议和基本被其独占的 IB 网络组成,这也即是老黄说的 AI Factory 推荐的互联方式,也是本文标题所指的 EtherNOT 互联。
介绍完主机之间互联,接下来我们将介绍主机之外的各种互联。如果你对于网络不是很熟悉的话,我们先一起认识一下物理世界中这些互联所需的网络设备。
首先是交换机,自从 Broadcom 在 2022 年发布 51.2T Tomahoawk5 交换机芯片23,进入 2023 年,目前主流交换机芯片已经支持 51.2Tbps 网络,如下所示:
2023 年云栖大会,阿里也发布了自己的 51.2T 交换机白盒交换机,下图中列出了一些关键参数,其中有一些指标对于不搞网络的同学可能不太熟悉,这里解释如下:
- 支持 128 个 400 GE 的网络端口,支持 400GE QSFP112 2425封装的光模块26
- SONiC 是一款开源的网络操作系统27,由微软发起并捐赠给 OCP,基于 Linux ,建立在交换机抽象借口之上,可运行在各种交换机和 ASIC 之上。

Source: From Vision to Execution: the story of Alibaba’s home-built 51.2T Switch, OCP 2023
光模块工作在物理层,实现光电转换,具体互联相关组件如下所示:

有了交换机、光模块、AOC 线缆之后,怎么将集群的这些服务器互联起来呢?目前数据中心主导的网络架构为 CLOS 架构,也称 Spine-Leaf 架构,如下所示:
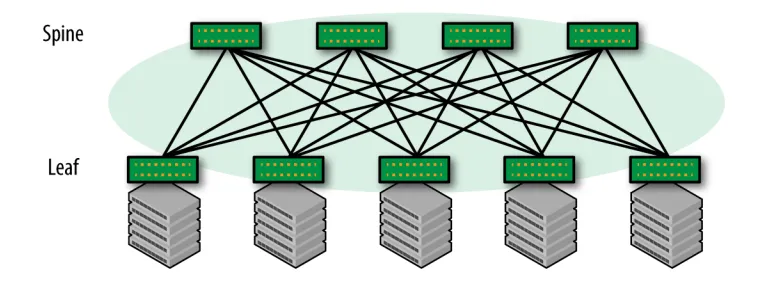
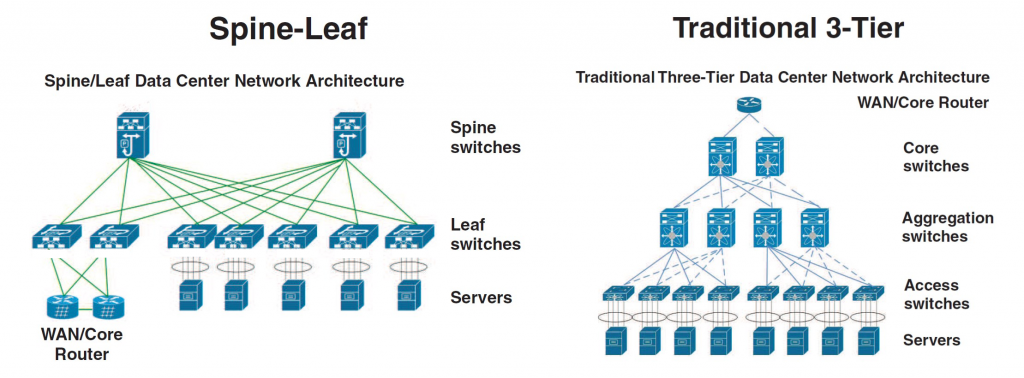
上面展示的是两层 CLOS 网络,然而随着集群节点数增加,有时候我们会构建三层乃至四层 CLOS 架构去构建更大的集群。
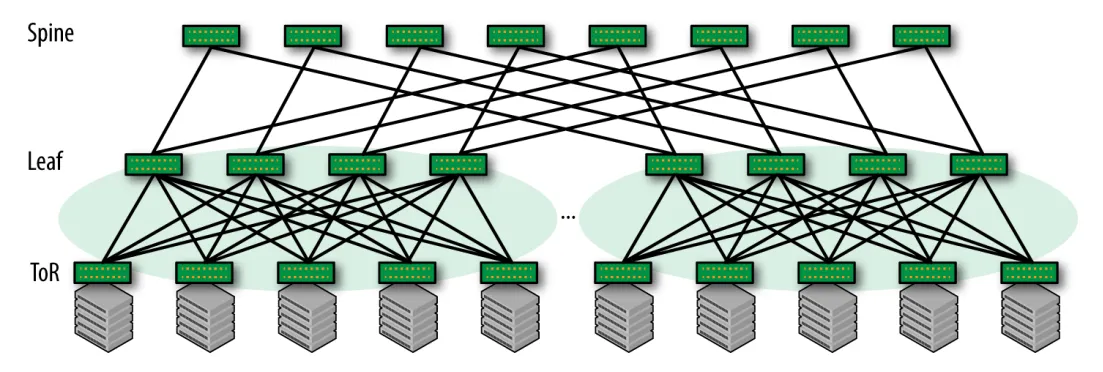
以百度的 AIPod 为例28,每个通道采用 2 级全互联 CLOS 架构,最多支持 512 卡,为了支持更大规模的集群,不同通道需要通过第三级交换机互联,一个集群最多支持 16k GPU。
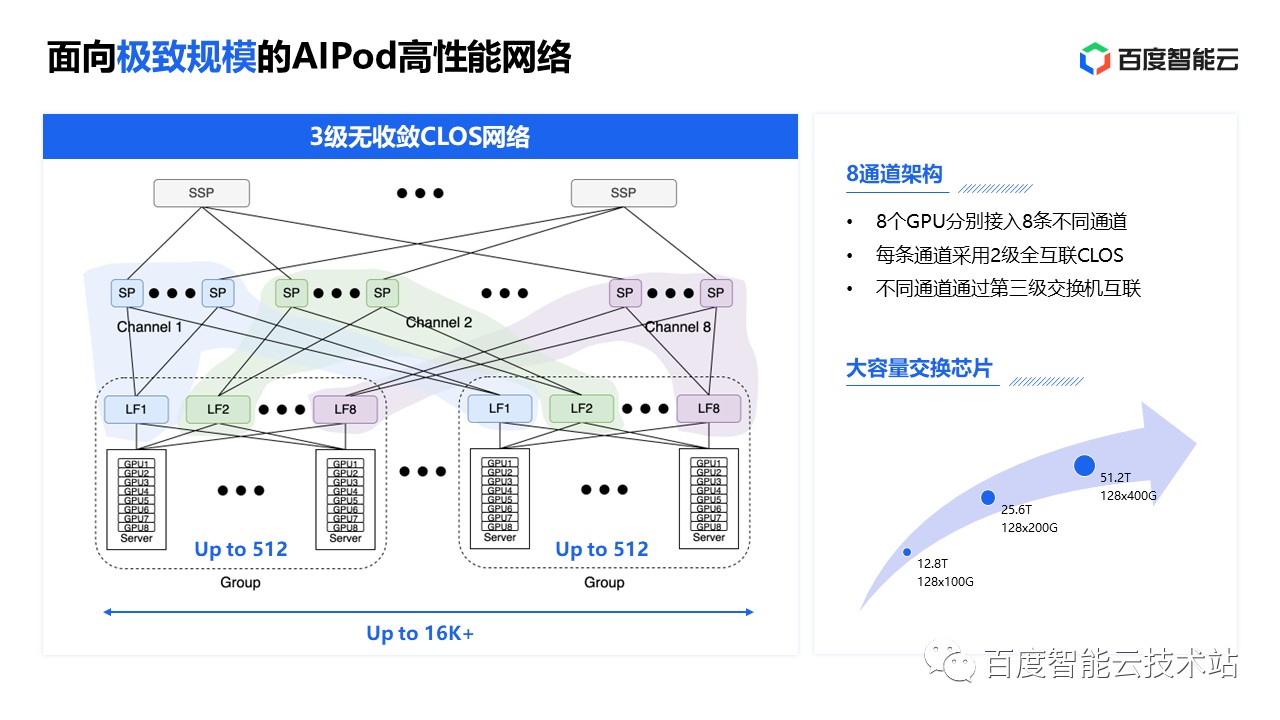
下一代 AI Infra 的互联需求
自从 2017 年百度的研究 Bringing HPC Techniques to Deep Learning30 ,在很多时候,我们喜欢将 HPC 和 AI 集群放在一起来说。这很合理,HPC 实施所要求的架构与 AI 非常相似,通常两者都需要处理规模不断增长的海量数据集,以获取分析结果,因此两者都需要高水平的计算与存储能力、大内存容量和带宽,以及高带宽网络架构。现在 AI 集群中应用广泛的 InfiniBand 互联网络31、MPI 并行计算范式32 等最早也是在 HPC 超算集群中得到使用。与此同时,AI 的发展也在促进着 HPC 的发展33。
然而,随着深度学习的进一步发展,AI 与 HPC 开始出现分野,Bill Dally 在 HotInterconnect 2023 演讲中指出了二者的不同:
- 相对于科学计算 FP64 的高精度计算,目前深度学习中经常使用 FP16 乃至更加低精度 FP8 等进行计算
- 科学精算经常受限于内存带宽,但是深度学习还会受限于计算与通信
- 值得注意的是,目前大规模深度学习训练3D 并行模式十分确定,其流量特征也是持续且可预期的

Credit: Accelerator Clusters, The New Supercomputer, Bill Dally, HotI 2023
本节将针对深度学习的典型场景,简单讨论目前 AI 对于互联网络的新需求。
首先是多轨道组网,也称作 Rail-Optimized InterConnect。传统互联中,一般是同一台机器的网卡连接相同的交换机。而多轨道组网中则是同一 GPU 编号对应的网卡上联到同一台 ToR 交换机。目前 AI Infra 中主流采用的是这种 Rail-Optimized 的 Clos 互联架构34。
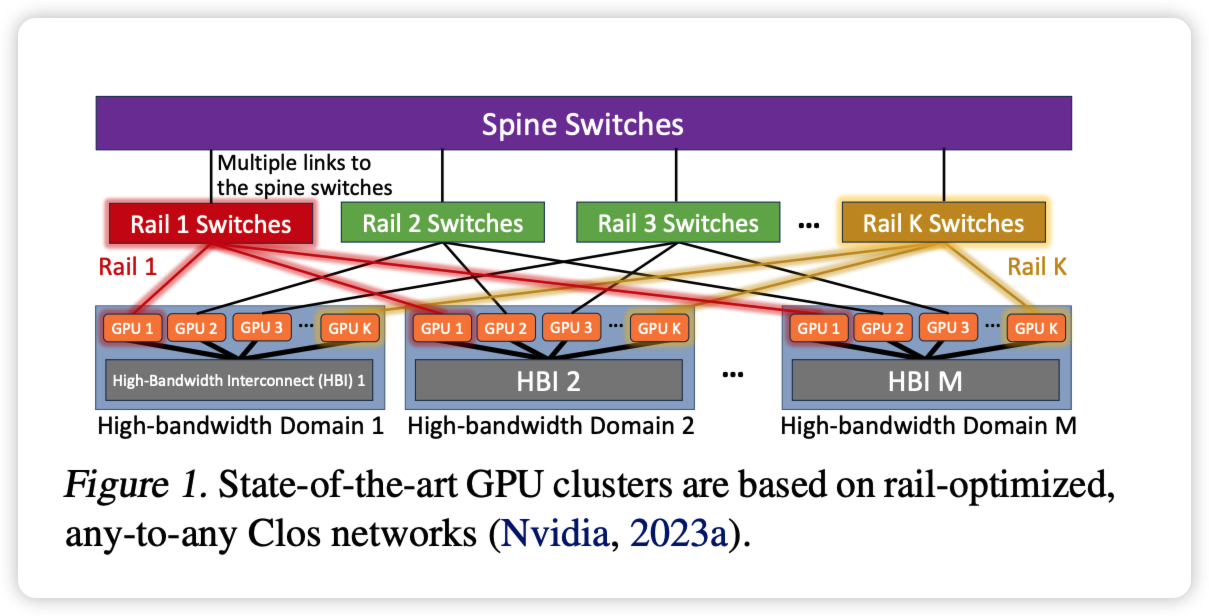
为什么要采用这种互联方式呢,而且这种互联方式故障影响半径还是更大的。如前所述,数据并行中往往是同节点的同号 GPU 进行通信,通过 rail-optimized 的互联方式,可以在同号卡之间尽量减少跨网络的跳数,降低跨 S0 通信量和哈希冲突概率。
多轨通信技术本质是将单个服务器节点内的 NVLink、节点间的高性能网络等互联资源统筹,在集群的尺度内逼近网络通信性能的极限。29
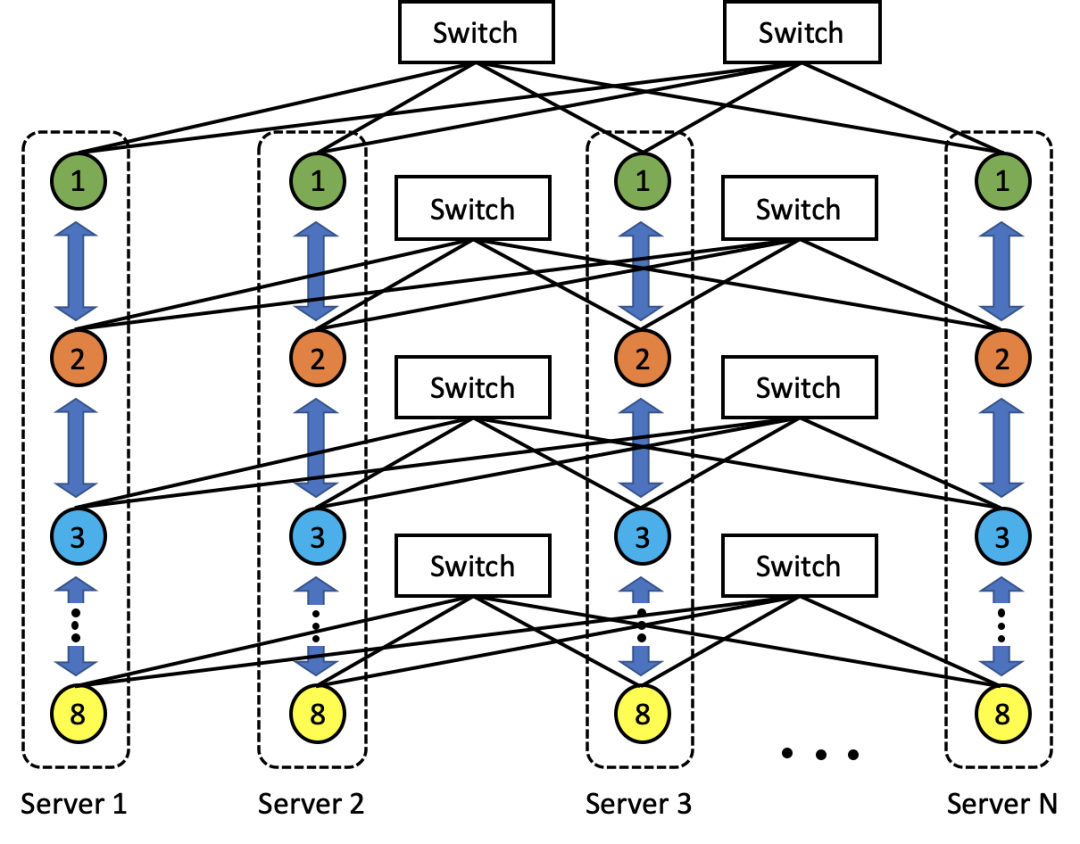
第二个是哈希选路冲突问题。交换机转发报文时,为了避免乱序重传,通常通过哈希算法将同一条连接的报文会向一条路径转发。现在业界做的比较好的是阿里的单层千卡的网络,可以实现千卡训练只在单 S0 下通信。但是目前实际的大模型训练往往可能有几千卡乃至上万卡训练,这种情况下必然会有跨交换机通信。
当规模增大,哈希也是有冲突的,参考百度的这张图,2 个跨交换机的连接如果同时选择了左边这个链路,那么就会导致左边链路拥挤而右边的链路空闲,这样两个连接的带宽都会减半。
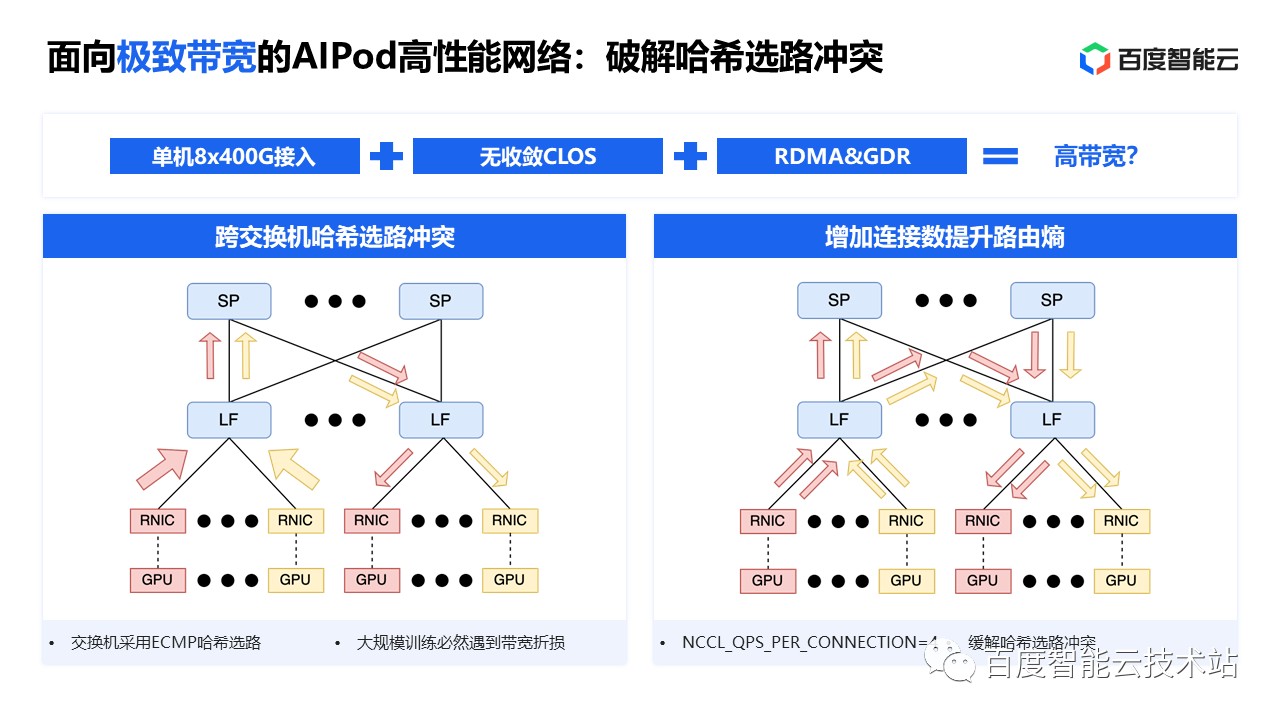
为了避免这个问题,常见的做法有几种:
- 通过设置
NCCL_QPS_PER_CONNECTION来使得 NCCL 通信库中两个 GPU 之间实现多个连接 - 通过修改 NCCL 这种集合通信库,让 NCCL 建立通信拓扑时能够感知网络架构,实现更高效通信互联
- 上层任务调度系统将不同 DP 组调度到合适的网络交换机下
这几种方法都可以缓解部分哈希冲突,但不能从根本上解决问题。如果想彻底解决这个问题,就需要用到网络的多路径转发能力。也就是允许报文的乱序接收,从而打破单连接报文只能选择一个路径这种假设。Infiniband 网络里面引入了这种多路径转发能力,叫做自适应路由 Adaptive Routing,可以通过感知不同路径的实时负载,将流量以包的颗粒度分发至不同路径,从而实现理想的负载均衡。
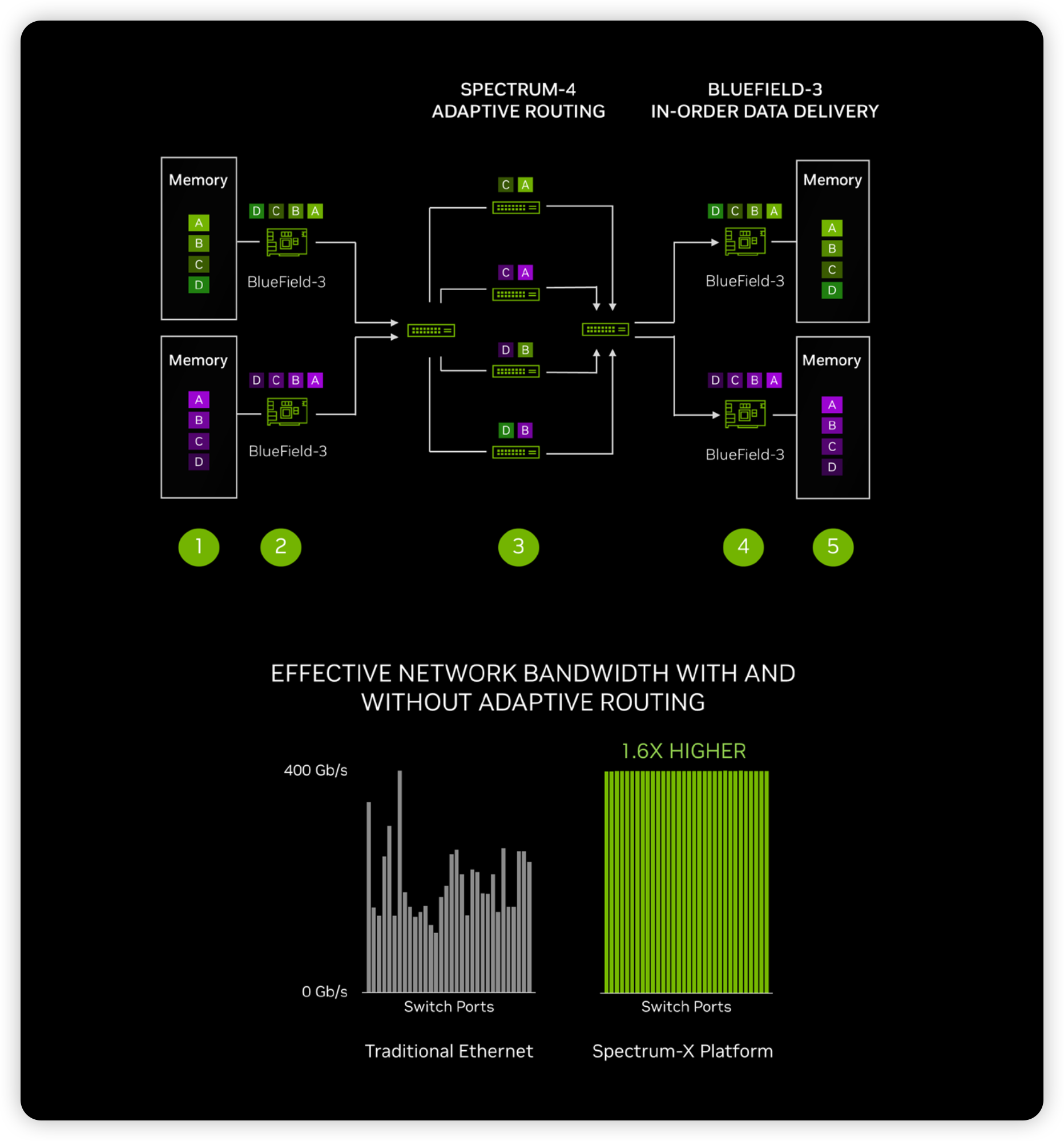
随着以太网的发展,新一代的以太网交换芯片和网卡芯片也具备像 IB 网络一样的自适应路由功能。NVIDIA 的 Spectrum-4 和 BlueField-3 即可实现在无损以太网中实现 RoCE 的 Adaptive Routing35 :
- BlueField-3 sends data into the switch network
- Spectrum-4 spreads the data packets across all available routes
- BlueField-3 ensures in-order data delivery
- Results in highly effective data throughout and short tail latency
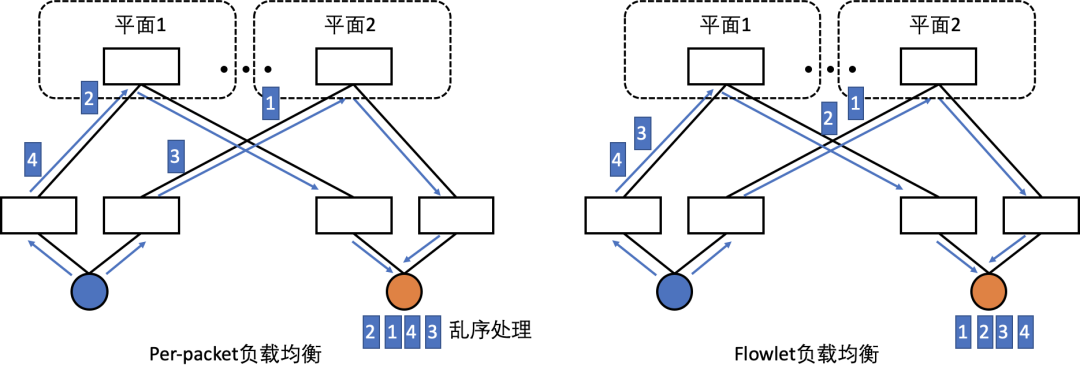
具体的负载均衡方案可以分为 Per-packet 粒度和 Flowlet 粒度两种,业内也都在尝试基于以太网去实现对应的自适应路由能力2930。
- Per-packet 路径选择可以做到最细粒度的负载均衡,代价是大幅度增加数据包乱序风险,最终传输性能依赖于端侧的解乱序能力
- Flowlet 粒度的负载均衡可以保证同一个流在时间上相邻的数据包通过相同路径传输,避免乱序出现,但是可能导致网络负载无法完全均匀地打散至所有路径上
本节简单介绍了当前大规模深度学习训练对于网络基础设施提出的需求与挑战,包括高带宽通信、网络拓扑优化、多路径自适应路由转发等能力。面对动辄成千上万卡的训练,也对网络的稳定性提出了要求,不仅仅是上万个 GPU,上万个光模块、众多的 AOC 线、相对复杂的无损以太网络,这些都有可能出现故障。故障是不可能避免的,如何能够快速发现故障、如何快速从故障中恢复、如何构建可观测平台,也是一个重要的问题,此处暂时不表。
EtherNET 还是 EtherNOT
五十年前,以太网起源于互联网技术源泉之一的施乐 Xerox 研究中心36,以简洁和开放的架构战胜众多专有网络,通过标准化和规范化成为 TCP/IP 网络的基石。
二十五年前,受限于 PCI 总线带宽瓶颈,由微软、Intel、IBM、Sun、Compaq、HP 等巨头公司组成的 InfiniBand 联盟 IBTA 提出 Infiniband 互联架构,试图取代 PCI、以太网等成为统一的互联方案31。然后,因为随之而来的互联网泡沫,如此巨大的野心在泡沫破裂后看起来过于激进,Intel 重新回到 PCI 专注于新的 PCIe 互联方案,并把持着基于 CPU 的互联直到现在,微软则抛弃 IB 选择 Ethernet 并最终支持其成为主流互联方案。只有部分公司仍然支持 IB 网络,成立 OpenFabrics Alliance37 ,并终于在超算集群中站稳脚跟。
十年前,Intel 把持着 PCIe 协议,各种 PCIe 设备之间的数据直通都要经过 CPU,并且其带宽演进也被严格限制。GPU 同样作为 PCIe 设备,备受限制,于是老黄提出 NVLink 协议实现 GPU 之间绕过 CPU 直接互联,大幅提升 GPU 之间通信带宽。此后 NVIDIA 脚踏实地迭代 NVLink21,并最终将集内的 NVSwitch 做到了机外,推出 NVLink Network,向上打 Infiniband,向下吃 Chiplet,遵循着 PCIe 规范一步一步将 GPU 做成主机上最有价值的部分,成为新生者挑战上一代霸主成功的典型案例。

尽管 Intel 在 2012 年收购了另一家玩家 QLogic,其后在 Infiniband 的投入并不太多。2019 年,NVIDIA 收购 Mellanox,Infiniband 虽然是开放组织,实际上的玩家也只剩 NVIDIA,结合其 NVLink Network,在互联上 NVIDIA 也成为了新一代的霸主。
面对新一代工作负载,老黄提出两种新的计算范式:
AI Factory:这即是前面提到的 DGX SuperPod 的方式,即是EtherNOT的互联方式AI Cloud:通过 Spectrum-X Ethernet 满足云上 AI workload 的互联需求,即是EtherNET的互联方式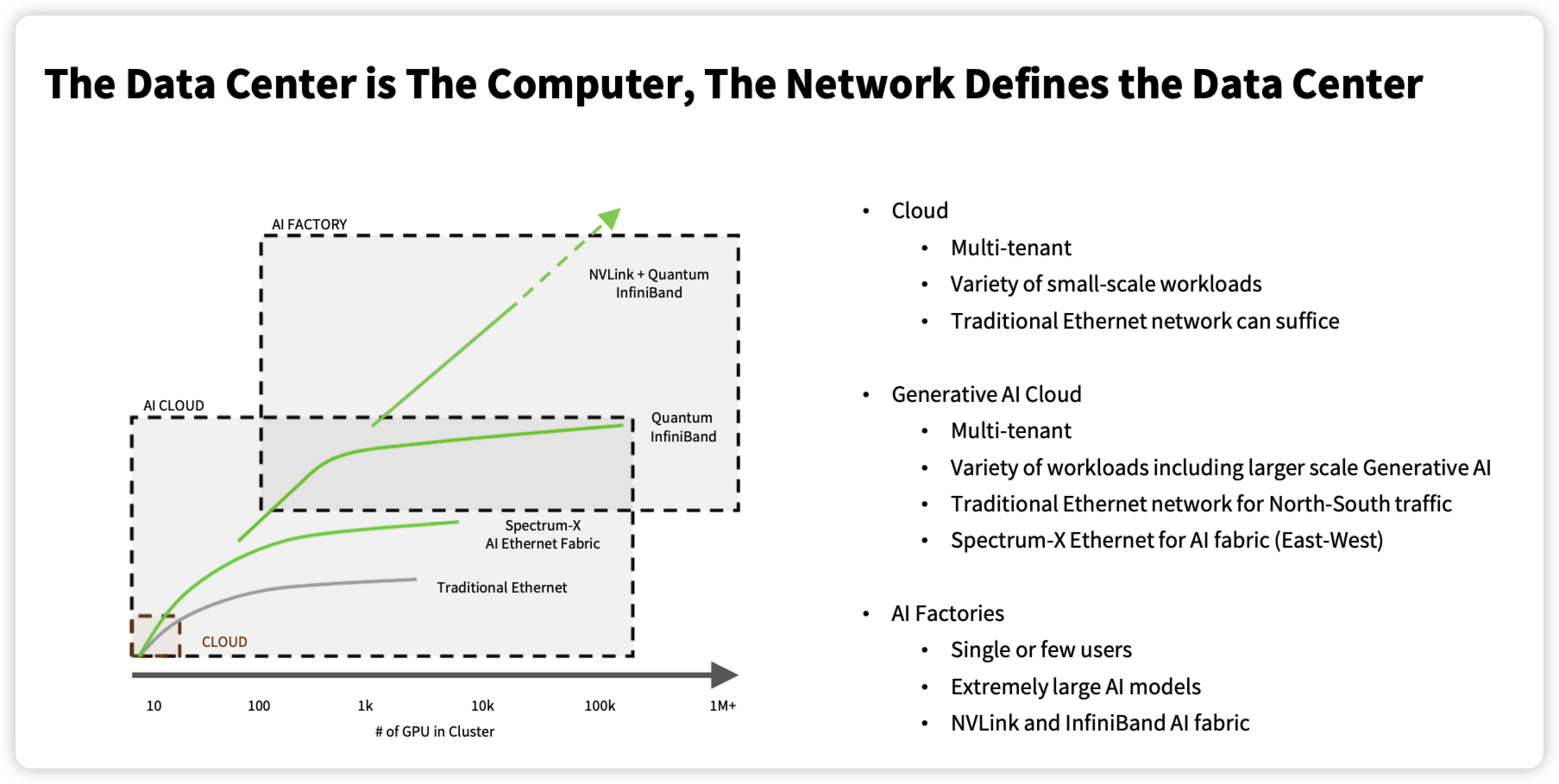
老黄一如既往的想打包卖整个系统的心思大家也都心知肚明,AI Factory 这一套互联方式不仅仅需要购买 Mellanox 的网卡,还需要打包整个交换机系统。InfiniBand 这套性能确实厉害,然而,网络互联作为互联网基础设施中最核心的技术,各大云厂商和科技公司怎么甘心被 NVIDIA 的 InfiniBand 和 NVLink 割韭菜。
是的,时代变了。随着 Gen AI 的进一步发展,不仅仅是上层模型应用,底层计算设备、网络互联等或许都来到了一个十字路口,产业的变革就在现在。
今年 7 月,由云厂商、系统厂商和半导体公司等主导成立了超级以太网联盟 Ultra Ethernet Consortium38,试图基于已经有 50 年历史的以太网,吹响针对 IB 的号角

面对新挑战,Intel 也不得不松动 PCIe 互联方案,联手 Dell、HP 推出新的互联标准 CXL41,在兼容 PCIe 的基础上尝试构建新的生态。另一方面,尽管作为 Infiniband 的发起方之一,也积极拥抱超级以太网联盟 UEC,与 AMD 一起共同作为 UEC 的创始成员。正所谓,敌人的敌人就是朋友。
除去 NVIDIA、AMD 和 Intel 这三个老冤家,各大互联网厂商在网络互联上也都有自己的想法。

Meta 一方面购买了 NVIDIA 的 Infiniband,一方面也在尝试基于 RoCEv2 来构建自己的 AI Infra,比如他们大受欢迎的 LLaMA2 既有来自 IB 网络训练,也有来自 RoCEv2 的网络训练而来42。

同为 UEC 的创始成员,Meta 拼命用 LLaMA 证明了 Ethernet 也可以作为当前大模型训练的底座。
What unites these companies – Broadcom, Cisco Systems, and Hewlett Packard Enterprise for switch ASICs (and soon Marvell we think), Microsoft and Meta Platforms among the titans, and Cisco, HPE, and Arista Networks among the switch makers – is a common enemy: InfiniBand.43
“So funny enough, the most important property is buildability,” Lapukhov said… So from my perspective, you have Ethernet and InfiniBand as two poles, but they solve the problem in different ways. Ethernet offers you an open ecosystem, multiple vendors, and easier supply sources to get your hardware. InfiniBand offers you the pedigree of technology used in HPC clusters, but there is only one supplier as of today. So the answer is, whatever you can make work on the timescale you need. So for us for longest time, it was Ethernet. We built many fabrics on Ethernet because this is technology we are familiar with good supply and we have had devices to deploy on time. And that took precedence…43
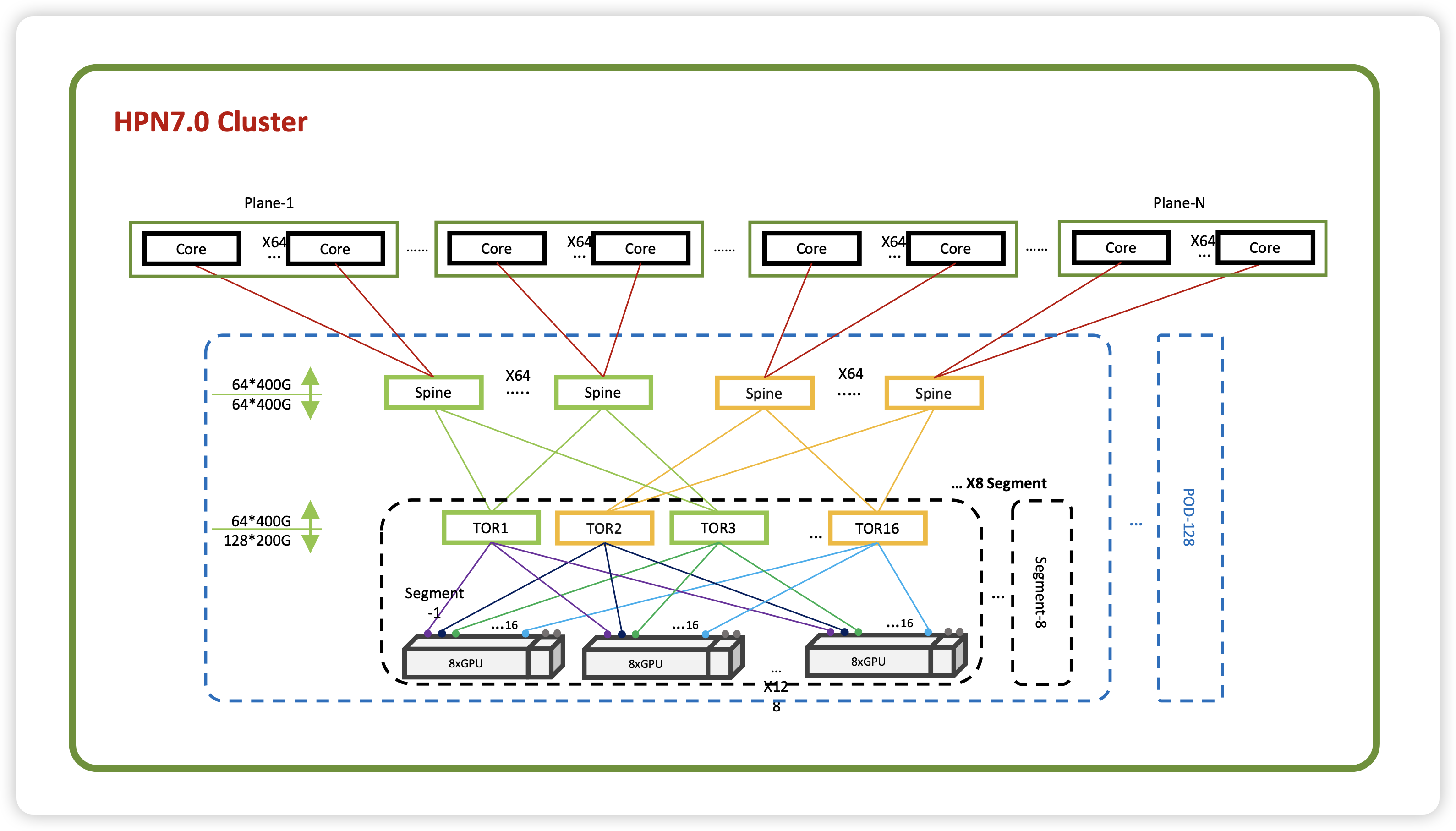
回到国内,阿里在 2023 云栖大会发布 HPN 7.0 的时候,专门提到了 UEC,表明自己沿着 Ethernet 向前走的决心。

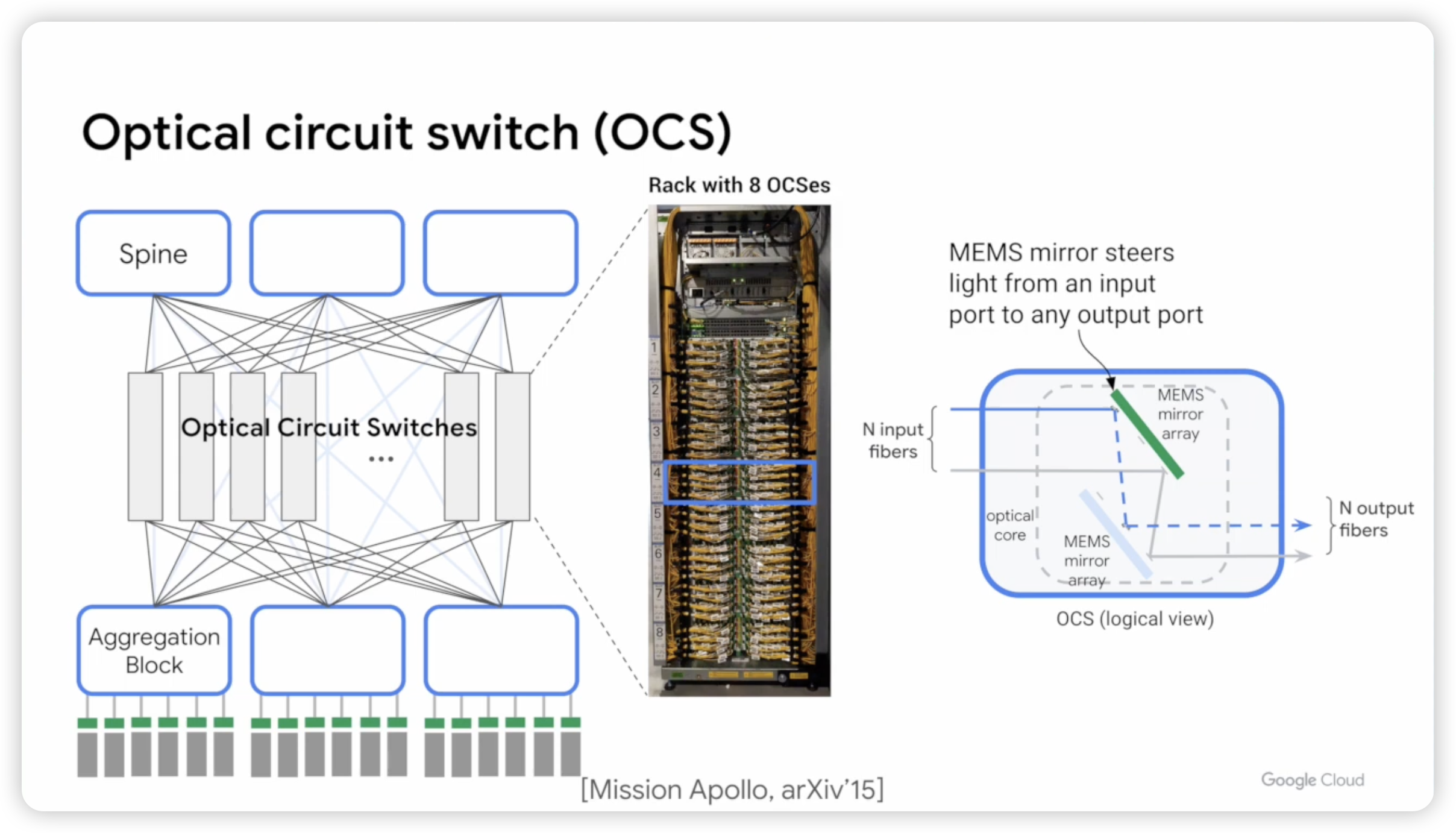
技术上一向特立独行的 Google,在其 TPUv4 集群中采用光交换 OCS,并且不再采用 CLOS 架构4445。不再使用 CLOS 架构是因为 CLOS 架构一般更合适于特征不可预期的流量,但是对于深度学习训练这种流量而言,其网络流量特征是可预期的。可预期网络,也正是阿里云在云栖大会所重点指出的一点。
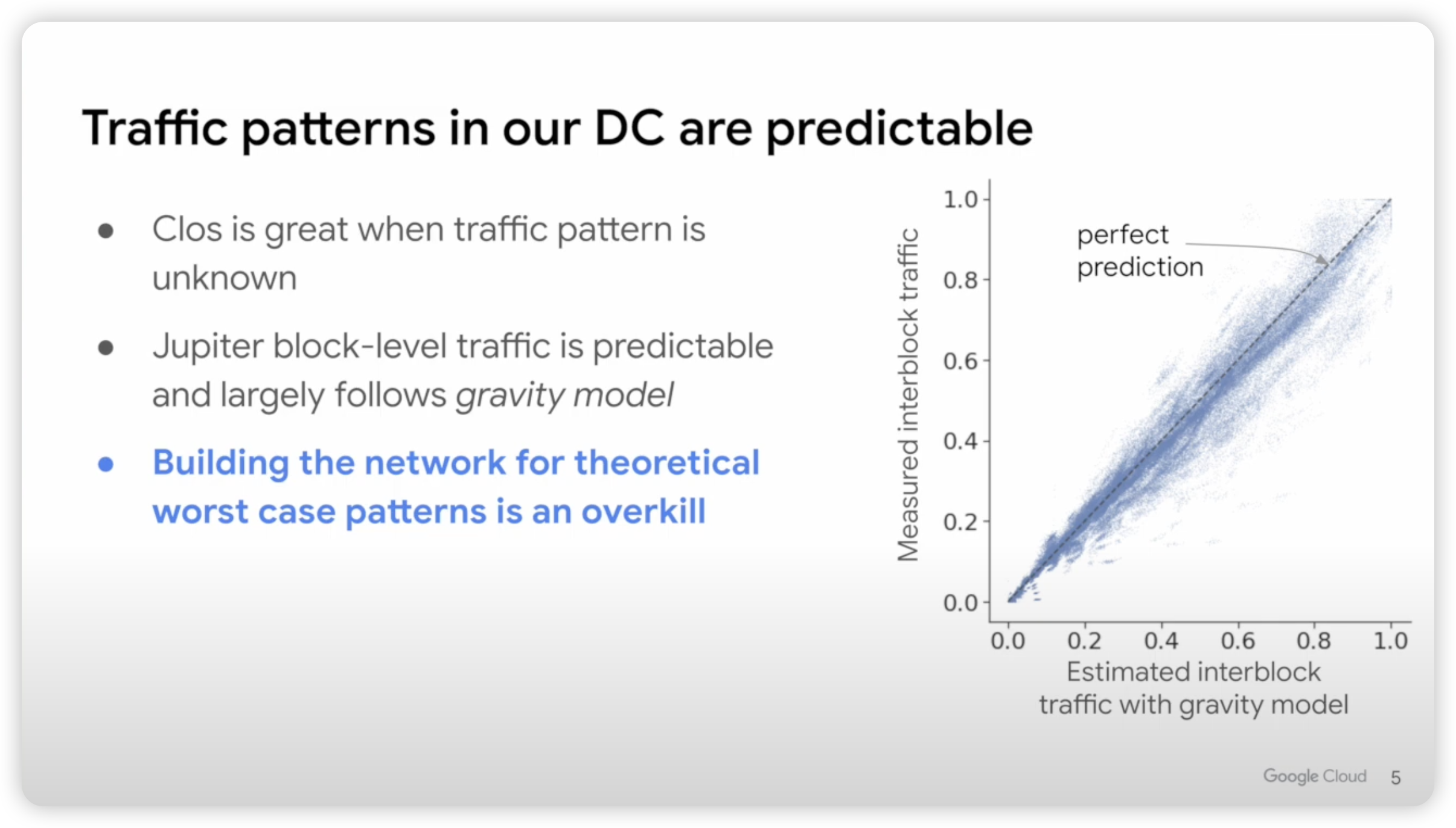
大模型目前结构越来越固定,并行训练通常也是 TP+PP+DP+MoE,为了实现计算与通信的 Overlap 一般通信也都是发生在不同节点的同号 GPU 上,网络流量的特征也十分明确,尽管光交换切换慢,对于 AI 这种场景却十分合适,还可以大幅度节省成本46。
无独有偶,尽管 NVIDIA 现在还卖着 NVLink + Infiniband,Bill Dally 已经在 HotI 2023 指出了 Nvlink-Network + DragonFly+OXC 方案47,试图指明下一代 AI Factory 的网络互联。

所以,未来会是怎样的呢?是 EtherNET 还是 EtherNOT?Infiniband 将来会主导 AI DC 网络互联吗?很喜欢苏妈的一句话「I’m not a believer in moats when the market is moving as fast as it is…」整个产业都还在迅速变化中,曾经的王者或许在下一个十年不得不成为新的追随者,让我们拭目以待。
Anyway, We are in a once-in-a-generation inflection point in computing, and networking
-
https://www.oracle.com/news/announcement/nvidia-chooses-oracle-cloud-infrastructure-for-ai-services-2023-03-21 ↩︎
-
https://nvidianews.nvidia.com/news/nvidia-and-microsoft-to-bring-the-industrial-metaverse-and-ai-to-hundreds-of-millions-of-enterprise-users-via-azure-cloud ↩︎
-
https://nvidianews.nvidia.com/news/google-cloud-and-nvidia-expand-partnership-to-advance-ai-computing-software-and-services ↩︎
-
https://nvidianews.nvidia.com/news/nvidia-launches-dgx-cloud-giving-every-enterprise-instant-access-to-ai-supercomputer-from-a-browser ↩︎
-
https://www.reuters.com/technology/amazons-cloud-unit-is-considering-amds-new-ai-chips-2023-06-14/ ↩︎ ↩︎
-
ZeRO, Zero Redundancy Optimizer, Microsoft, https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/ ↩︎
-
https://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.ShardingStrategy ↩︎
-
Reducing Activation Recomputation in Large Transformer Models, https://arxiv.org/pdf/2205.05198.pdf ↩︎
-
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM: https://arxiv.org/pdf/2104.04473.pdf ↩︎
-
https://github.com/NVIDIA/Megatron-LM/blob/2bc6cd307a11423928c675f741e79e03df23e721/megatron/core/pipeline_parallel/schedules.py#L1052-L1298 ↩︎
-
https://github.com/NVIDIA/Megatron-LM/blob/2bc6cd307a11423928c675f741e79e03df23e721/megatron/core/pipeline_parallel/schedules.py#L367-L940 ↩︎
-
Mixture of Experts Explained, https://huggingface.co/blog/moe ↩︎
-
Tutel: Adaptive Mixture-of-Experts at Scale, https://arxiv.org/pdf/2206.03382.pdf ↩︎
-
Janus: A Unified Distributed Training Framework for Sparse Mixture-of-Experts Models, https://dl.acm.org/doi/pdf/10.1145/3603269.3604869 ↩︎
-
HetuMoE: An Efficient Trillion-scale Mixture-of-Expert Distributed Training System, https://arxiv.org/pdf/2203.14685.pdf ↩︎
-
Accelerating Distributed MoE Training and Inference with Lin https://www.usenix.org/system/files/atc23-li-jiamin.pdf ↩︎
-
https://github.com/NVIDIA/NeMo/blob/main/docs/source/nlp/nemo_megatron/parallelisms.rst ↩︎
-
https://en.wikipedia.org/wiki/Intel_Ultra_Path_Interconnect ↩︎
-
nvlink 那些事, https://zhuanlan.zhihu.com/p/639228770 ↩︎ ↩︎
-
https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/ ↩︎
-
https://www.broadcom.com/products/ethernet-connectivity/switching/strataxgs/bcm78900-series ↩︎
-
https://community.fs.com/article/what-is-qsfp112-and-400g-qsfp112-transceiver.html ↩︎
-
What Is an Optical Module and Its FAQs https://support.huawei.com/enterprise/en/doc/EDOC1100130737 ↩︎
-
百度,大规模 AI 高性能网络的设计与实践, https://cloud.baidu.com/article/364290 ↩︎
-
灵骏可预期网络:Built for AI Infrastructure, https://mp.weixin.qq.com/s/-QojHhmgM0-jqTYQUpkSgw ↩︎ ↩︎ ↩︎
-
Bringing HPC Techniques to Deep Learning, https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/ ↩︎ ↩︎
-
https://www.nvidia.cn/high-performance-computing/hpc-and-ai/ ↩︎
-
How to build low-cost networks for large language models (without sacrificing performance)? https://arxiv.org/pdf/2307.12169.pdf ↩︎
-
NVIDIA Spectrum-X Network Platform Architecture, OCP 2023, https://www.youtube.com/watch?v=GssE_bWDXAM ↩︎
-
https://ultraethernet.org/leading-cloud-service-semiconductor-and-system-providers-unite-to-form-ultra-ethernet-consortium/ ↩︎
-
https://www.amd.com/en/technologies/infinity-architecture ↩︎
-
AMD Presents: Advancing AI 2023, https://www.youtube.com/live/tfSZqjxsr0M?si=CHUliaEh1v9wNJF9&t=5137 ↩︎
-
https://engineering.fb.com/2023/11/15/networking-traffic/watch-metas-engineers-on-building-network-infrastructure-for-ai/ ↩︎
-
https://www.nextplatform.com/2023/09/26/meta-platforms-is-determined-to-make-ethernet-work-for-ai/ ↩︎ ↩︎
-
TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings, https://arxiv.org/pdf/2304.01433.pdf ↩︎
-
Jupiter Evolving: Transforming Google’s Datacenter Network via Optical Circuit, https://cloud.google.com/blog/topics/systems/the-evolution-of-googles-jupiter-data-center-network ↩︎
-
从 HOTI 到 AI-I 架构, https://zhuanlan.zhihu.com/p/659017509 ↩︎
-
Keynote by Bill Dally (NVIDIA): Accelerator Clusters, https://www.youtube.com/watch?v=napEsaJ5hMU ↩︎

alipay

Author houminwei
Publish January 7, 2024
LastMod February 15, 2024
License 本作品采用 CC BY-NC-ND 4.0 许可协议进行许可,转载时请注明原文链接
如果你在浏览博客的过程中发现了任何问题,欢迎在对应文章下评论。如果你有其他事情想要咨询,可以通过邮件联系我。
